
Ihre Cloud, Ihr Weg: Private, Public und Hybrid Cloud oder Dedicated Server
Managed Cloud Hostingmit kompromissloser Performancevon centron
centron setzt Maßstäbe in Deutschland durch GDPR-konforme Managed Cloud-Lösungen und Sichere & Skalierbare IT-Services. Von S3 Storage bis zu dedizierten Servern – leistungsstark, zuverlässig, rechtssicher. Managed Cloud Hosting für zukunftsorientierte Unternehmen. Unser Versprechen: Performance, Service-Qualität und Rechtssicherheit.
#1
Agile Cloud Service Provider
+2400
Zufriedene Kunden
24/7
Experten Support
5
Redundante Datacenter
Kundenstimmen im Fokus
Echte Meinungen. Echte Resultate.
★★★★★ Toller Support, super Preis / Leistungs-Verhältnis
Wir sind vor 3 Monaten von Azure mit deren App-Service-Plan zu Managed Servern von Centron gewechselt. Seitdem haben wir keine Performanceprobleme mehr und das bei einem deutlich günstigeren Preis.
Robert Lassen
Flowmium GmbH
★★★★★ Umzug unseres ERP-Systems auf die Centron-Server war erfolgreich!
Vielen herzlichen Dank an alle Beteiligten für den erfolgreichen Umzug und für die angenehme Zusammenarbeit! Ich freue mich auf mögliche weitere Projekte, die wir in Zukunft zusammen umsetzen werden.
Doris Kühnel
Kanal Oberreiter GmbH
★★★★★ Know-How & das Gefühl, gut aufgehoben zu sein!
Die Freundlichkeit und das fachliche Know-How der Mitarbeiter ist super. Mit meinen hauptsächlichen drei Ansprechpartnern bei Centron bin ich sehr zufrieden. WEITER SO!
Orhan Güner
Markel Holdings GmbH
Features, mit denen Sie skalieren können
Von einfachen Tools und kalkulierbaren Preisen bis hin zum Support für wachsende Unternehmen
ist die Cloud von centron auf die besonderen Bedürfnisse von Startups und KMUs zugeschnitten.

Schnellere Entwicklung und Bereitstellungmit einfachen Tools
Unsere Produkte, wie Kubernetes, ccloud³, und Managed Cloud Hosting, zeichnen sich durch ihre Einfachheit aus und ermöglichen es Ihnen, sich voll und ganz auf die Entwicklung von Anwendungen zu konzentrieren.

Profitables Wachstum mitvorhersehbaren Cloud-Kosten
Für einen ROI, der neue Maßstäbe setzt, mit vorhersehbaren Cloud-Kosten. Kalkulierbare Preisgestaltung durch unsere S3 Object Storages, behalten Sie die Ausgaben mit unseren Management Tools im Griff. Beispielhaft stehen Optimierung der Kontingente & Advanced Monitoring, sowie Backups & cBacks.

Reduzieren Sie Ihre Hindernissemit engagiertem Support
Bei centron stehen wir immer zu Ihrer Seite! Mit kostenlosen, personalisierten Support oder über unsere kostenpflichtigen Tarife für spezielle Hilfe und schnellere Reaktionszeiten. Zudem stehen Ihnen zahlreiche Ressourcen und Tutorials zur Verfügung.

Verbessern Sie die Kundenerfahrung durch das Bauen auf einer zuverlässigen Plattform
UX und UI Optimierung durch zuverlässige Plattformen sind unser täglich Brot. Ob es sich um Virtuelle Maschinen über unsere ccloud³, welche minimale Ausfallzeiten garantieren, oder unsere Managed Server und S3 Object Storage – zusammen bieten wir mit unseren Dedicated Servern und Cloud GPU für das KI-powered Business intuitive Produkte für eine hervorragende Kundenerfahrung.
Starten Sie noch heute mit centron und transformieren Sie Ihre Geschäftsinfrastruktur.
Mit centron's Managed Cloud Hosting haben Sie alles, was Sie für ein nahtloses, skalierbares Wachstum benötigen - von einfachen Tools bis hin zu kalkulierbaren Kosten. Melden Sie sich jetzt an, um Ihren Weg zu einer zuverlässigeren, sichereren und skalierbaren Cloud-Infrastruktur zu beginnen. Erhalten Sie Zugang zu personalisiertem Support und nutzen Sie unser 100 € Startguthaben für neue Kunden.
Eine Cloud für Ihre gesamte Reise
Die Managed Cloud Hosting Produktpalette von centron ist so konzipiert, dass sie Sie bei jedem Schritt
auf Ihrem Weg begleitet, egal ob Sie ihn selbst gehen oder sich von Experten helfen lassen möchten.

Managed Server
High Performance Server ohne Administrationsaufwand. Fokussieren Sie sich auf Ihre Projekte, wir kümmern uns um die Einrichtung, Backups, Monitoring & Updates.

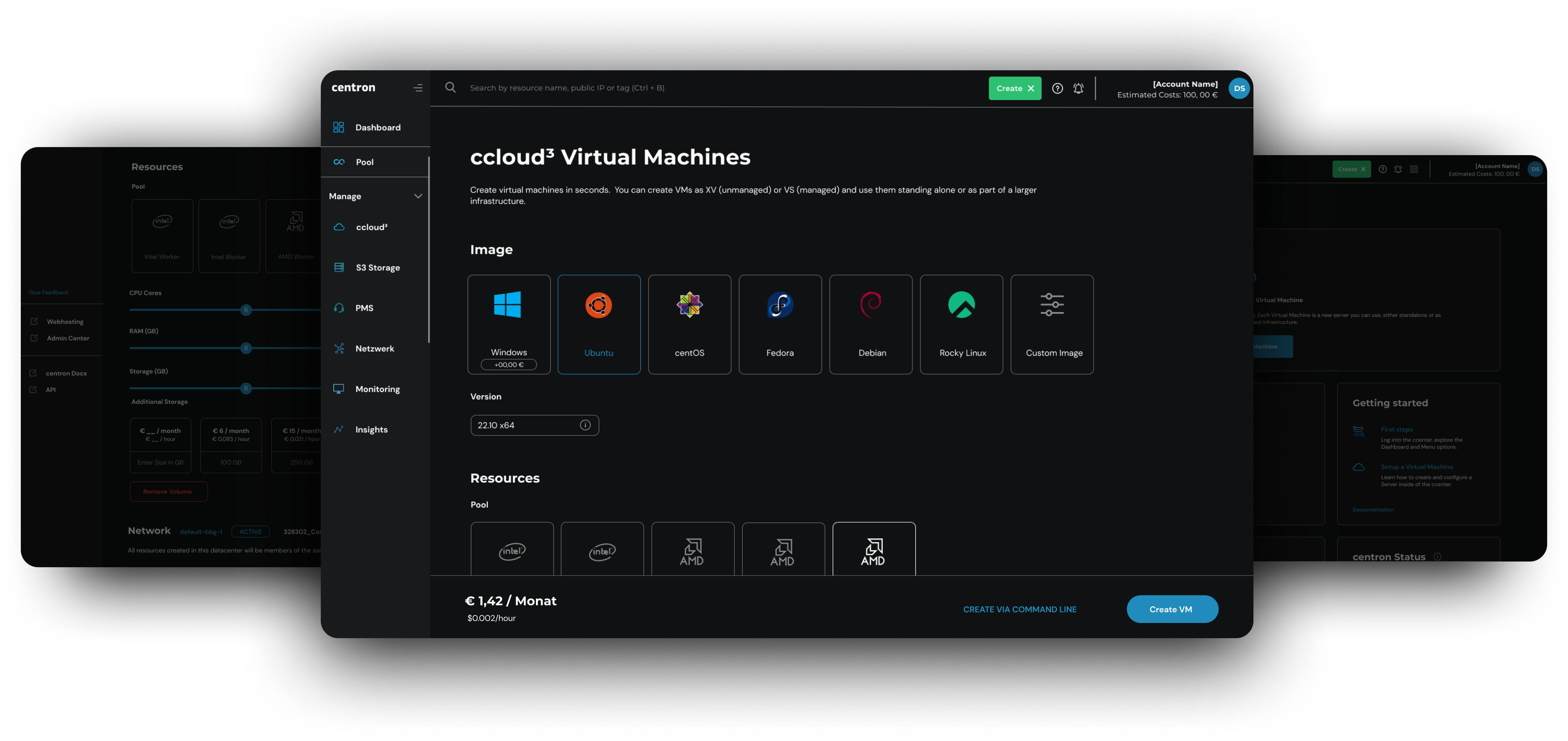
Virtual Machines
On-demand Linux oder Windows VMs von centron bieten Ihnen die Wahl zwischen all-purpose Worker Pools und high-performance Power Pools.
Kubernetes
Ein benutzerfreundlicher Kubernetes Service von centron, der Ihnen Zuverlässigkeit, Skalierbarkeit und Portabilität für Ihre cloud-nativen Apps bietet.

S3 Object Storage
Speichern und skalieren Sie große Datenmengen, ohne sich um Speicherbegrenzungen der Compute-Server sorgen zu müssen.
Cloud GPU
Die Cloud GPUs von centron bieten eine leistungsstarke und flexible Lösung für Ihre rechenintensiven Anwendungen.

Managed Firewall
centron Networking Experten übernehmen zusätzlich zu allen Features der Cloud Firewall Einrichtung, Wartung und Verwaltung Ihrer Firewall
Trust Center - Die Sicherheit Ihrer Daten hat für uns höchste Priorität
Zusätzlich zu unseren eigenen strengen Sicherheitsvorkehrungen hält sich centron an die hier aufgeführten veröffentlichten Standards.




Lernen Sie von den Experten
Egal, ob Sie mehr über die Finanzierung Ihres Unternehmens, die Installation von Linux auf Ubuntu oder die ersten Schritte mit centron erfahren möchten, wir haben die richtigen Ressourcen für Sie.

Product Docs
Erfahren Sie in der ausführlichen Dokumentation, wie Sie eine virtuelle Maschine aufsetzen, wie Sie mit Blockspeicher arbeiten und vieles mehr.
Business-Beratung
Business Advice von centron für Startup- und Business-orientierte Inhalte zu Finanzierung, Teambuilding und Skalierung.
Technische Expertise
Besuchen Sie die Tutorials von centron, um von einer breiten Palette technischer Tutorials und Informationen zu lernen und fortzubilden.
Managed Cloud Hosting in Deutschland: GDPR-konform, Sicher & Skalierbar mit centron
Unsere leistungsstarke, flexible Cloud-Dienste und Managed Hosting Lösungen zusammengefasst:
Managed Cloud Hosting & IT-Services: Sicherheit und Skalierbarkeit nach Maß
Komplettlösungen von centron bieten Höchstleistung in Sachen Managed Cloud Hosting und IT-Services, die nicht nur GDPR-konform sind, sondern auch speziell auf Sicherheit und Skalierbarkeit ausgerichtet sind. Mit Lösungen wie S3 Storage und dedizierten Servern bis hin zu effizienten Kubernetes Implementierungen bietet centron verlässliche und effiziente Technologie.
Performance und Compliance: Managed Cloud Hosting mit centron
Bei centron profitieren Sie von Managed Cloud Hosting, das nicht nur leistungsstark und ISO-zertifiziert ist, sondern auch strengste EU-DSGVO Standards erfüllt und durch erweiterte Dienste wie Managed Firewall und Cloud GPU Optionen eine maßgeschneiderte Performance sicherstellt.
IT-Outsourcing und Beratung: Expertenlösungen für effiziente IT-Strukturen
Profitieren Sie von den Kostenvorteilen und Effizienzsteigerungen durch unser IT-Outsourcing und die maßgeschneiderte Beratung, die nicht nur Ihre IT-Projekte gemäß ISO 27001 sicher gestaltet, sondern auch operative Belastungen reduziert. Unsere Experten bieten mit Managed Cloud Hosting und weiteren IT-Dienstleistungen praktische Lösungen zur Skalierung Ihres Unternehmens.
Infrastruktur und Speicherlösungen: Maßgeschneiderte Services für Ihr Datenmanagement
Unsere Managed Cloud Hosting und maßgeschneiderten Infrastruktur- und Speicherlösungen bieten zuverlässige Unterstützung für Ihr Unternehmen, inklusive RAID-Systemen und IaaS-Plattformen, ergänzt durch unsere fortschrittlichen Cloud-GPU und GPU Server für anspruchsvolle Datenanalysen und Recovery IT Services, die eine schnelle Datenwiederherstellung sicherstellen, alles zertifiziert nach ISO 27001 für höchste Datensicherheit.