
Hidden Markov Models: Theorie, Algorithmen, Python-Implementierung und moderne Alternativen
Hidden Markov Models (HMMs) sind probabilistische Modelle des maschinellen Lernens, die Muster in sequenziellen Daten erkennen können. Ein HMM geht davon aus, dass hinter den beobachtbaren Daten eine Abfolge verborgener Zustände liegt, die sich im Zeitverlauf verändert. Jeder dieser verborgenen Zustände erzeugt zusätzlich eine beobachtbare Ausgabe auf Basis festgelegter Emissionswahrscheinlichkeiten.
Diese Modelle eignen sich besonders gut, um verdeckte Strukturen in dynamischen Systemen zu analysieren, bei denen die eigentlichen Ursachen nicht direkt sichtbar sind und aus beobachtbaren Effekten abgeleitet werden müssen. HMMs können Unsicherheit und zeitliche Abhängigkeiten in Sequenzdaten abbilden. Dieser Leitfaden erklärt die Theorie hinter HMMs, darunter Übergangs- und Emissionswahrscheinlichkeitsmatrizen (EM), zentrale Algorithmen, die Implementierung von HMMs in Python sowie moderne Alternativen für die Sequenzmodellierung.
Wichtige Erkenntnisse
HMMs modellieren verborgene Ursachen hinter beobachtbaren Sequenzen: Sie basieren auf einem latenten Markov-Prozess, der nicht direkt sichtbar ist. Stattdessen wird dieser über Emissionswahrscheinlichkeiten mit den Beobachtungen verknüpft. Dadurch sind HMMs besonders geeignet, wenn nur Auswirkungen beobachtet werden können, nicht aber die tatsächlichen zugrunde liegenden Zustände.
Drei Kernaufgaben bestimmen die Nutzung von HMMs: Evaluation berechnet die Wahrscheinlichkeit einer Beobachtungssequenz mit dem Forward-Algorithmus, Decoding rekonstruiert die wahrscheinlichste verborgene Zustandsfolge mit dem Viterbi-Algorithmus, und Learning schätzt Modellparameter mit Baum-Welch oder EM.
Interpretierbarkeit ist eine große Stärke: Die Modellparameter wie Anfangswahrscheinlichkeiten, Übergangsmatrix und Emissionswahrscheinlichkeiten haben jeweils eine klare probabilistische Bedeutung. Dadurch sind HMMs verständlicher und intuitiver als viele tiefe neuronale Netze.
HMMs bleiben bei kleineren oder strukturierten Datensätzen praktisch: Sie können besonders effektiv sein, wenn nur begrenzte Daten verfügbar sind oder wenn Fachwissen die Übergänge vorgibt. Typische Einsatzbereiche sind Spracherkennung, Genomik und die Erkennung von Marktregimen im Finanzbereich.
Moderne Deep-Learning-Modelle führen den Grundgedanken weiter: Modelle wie RNNs, Transformer und hybride HMM-NN-Ansätze übertreffen HMMs in vielen groß angelegten Anwendungen. Dennoch verfolgen sie ein ähnliches Ziel: zeitliche Abhängigkeiten zu lernen und Unsicherheit über den Zeitverlauf hinweg abzubilden.
Was ist ein Hidden Markov Model?
Hidden Markov Models sind probabilistische Modelle für Sequenzdaten, bei denen ein verborgener beziehungsweise latenter Markov-Prozess beobachtbare Ausgaben erzeugt. In einem HMM besitzt jeder Zeitschritt einen verborgenen Zustand, der sich über Markov-Übergänge weiterentwickelt. Zusätzlich gibt es eine Emissionswahrscheinlichkeit, die bestimmt, welches beobachtbare Symbol oder Merkmal aus einem bestimmten verborgenen Zustand entsteht.
Markov-Ketten vs. Hidden Markov Models
Eine Markov-Kette ist ein einfacheres Modell. Sie besteht aus Zuständen und Übergangswahrscheinlichkeiten. Allerdings sind alle Zustände direkt beobachtbar. Würde man beispielsweise das Wetter mit einer Markov-Kette modellieren, könnten die Zustände „Sonnig“ und „Regnerisch“ heißen. In diesem Fall wäre das Wetter an einem bestimmten Tag direkt bekannt. Die Kette beschreibt dann die Wahrscheinlichkeit, von einem heutigen Zustand in einen morgigen Zustand zu wechseln.
In einem Hidden Markov Model sind die Zustände dagegen nicht direkt sichtbar. Stattdessen erzeugt jeder Zustand mit einer bestimmten Wahrscheinlichkeit eine Beobachtung. Im Wetterbeispiel bedeutet das: Sie leben in einer anderen Stadt und kennen das tatsächliche Wetter in der Stadt Ihres Freundes nicht. Das Wetter ist der verborgene Zustand. Sie erhalten jedoch einen Anruf, in dem Ihr Freund beschreibt, wie er sich fühlt. Tägliche Beobachtungen wie „glücklich“ oder „traurig“ geben Hinweise auf die Wetterlage in seiner Stadt. Der verborgene Wetterzustand beeinflusst die beobachtete Stimmung, doch das Wetter selbst sehen Sie nie direkt.
Zentrale Bestandteile eines Hidden Markov Models
Dieser Abschnitt dient als kompakte Legende für ein HMM-Diagramm. Er beschreibt die verborgenen Zustände, die beobachteten Symbole und die Wahrscheinlichkeitstabellen π, A und B. Diese legen jeweils den Start fest, steuern die Übergänge und erzeugen die Emissionen.
Verborgene Zustände: Zu jedem Zeitschritt t befindet sich das System genau in einer latenten Klasse s_i. Die Notation zeigt, dass der verborgene Prozess kategorial ist und N mögliche Regime besitzt. X_t wird selbst nie direkt beobachtet, sondern aus den Daten abgeleitet.
Beobachtungen: Zu jedem Zeitschritt gibt es ein beobachtbares Symbol oder eine Messung aus einem endlichen Alphabet. Das verdeutlicht, dass der sichtbare Datenstrom in diesem Fall diskret ist. In der Praxis ist O_t mit X_t verbunden: Unterschiedliche verborgene Zustände erzeugen unterschiedliche Beobachtungsmuster.
Anfangswahrscheinlichkeiten: Der Zeilenvektor π beschreibt die a-priori-Annahme darüber, wo die Sequenz beginnt. Jeder Wert πi gibt die Wahrscheinlichkeit an, dass der erste verborgene Zustand s_i ist. Die Normalisierung stellt sicher, dass es sich um eine gültige Wahrscheinlichkeitsverteilung handelt.
Übergangswahrscheinlichkeiten: Die Matrix A=[aij] beschreibt die Zustandsdynamik: Von Zustand i aus, welche Folgezustände j sind wahrscheinlich? Die zeilenstochastische Bedingung, bei der jede Zeile die Summe eins ergibt, stellt sicher, dass jede Zeile eine gültige bedingte Verteilung bildet. Die Bedingung auf X_t formuliert die Markov-Eigenschaft erster Ordnung: Der zukünftige Zustand hängt nur vom aktuellen Zustand ab und nicht von der gesamten vorherigen Sequenz.
Emissionswahrscheinlichkeiten: Für jeden verborgenen Zustand s_i beschreibt die Zeile bi(⋅) eine kategoriale Verteilung über die Beobachtungssymbole. Ist b_i(k) hoch, dann emittiert Zustand s_i häufig das Beobachtungssymbol o_k. Diese bedingte Struktur verbindet den unsichtbaren Prozess mit den beobachteten Daten.
Sequenzfaktorisierung: Die Produktform beschreibt im Kern die vollständige generative Geschichte. Zuerst wird mit π ein Startzustand gewählt. Anschließend wird mit B die erste Beobachtung erzeugt. Für jeden weiteren Zeitschritt wird mit A ein neuer Zustand ausgewählt und mit B eine Beobachtung emittiert.
Beispiel: Wetter- und Stimmungs-HMM
Um diese Bestandteile verständlicher zu machen, betrachten wir ein einfaches HMM-Beispiel. Die Stimmung Ihres Freundes hängt vom Wetter in seiner Stadt ab. Sie möchten dieses System modellieren. Es umfasst folgende Elemente:
- Verborgene Zustände: Das Wetter in der Stadt Ihres Freundes an jedem Tag. Zur Vereinfachung nehmen wir zwei Zustände an: Sonnig und Regnerisch.
- Beobachtungen: Die Stimmung Ihres Freundes an jedem Tag, entweder Glücklich oder Traurig.
- Zustandsübergangswahrscheinlichkeiten: Die Wahrscheinlichkeit, dass sich das Wetter von einem Tag zum nächsten ändert.
- Emissionswahrscheinlichkeiten: Der Einfluss des Wetters auf die Stimmung.
Nehmen wir an, das Modell ist wie folgt definiert:
# HMM Example: Weather and Friend's Mood
States (hidden): [Sunny, Rainy]
Observations: [Happy, Sad]
Transition probability matrix (A):
to Sunny to Rainy
Sunny 0.8 0.2
Rainy 0.4 0.6
Emission probability matrix (B):
Happy Sad
Sunny 0.9 0.1
Rainy 0.2 0.8
Initial state distribution (π):
Sunny: 0.5, Rainy: 0.5
Dieses HMM lässt sich folgendermaßen interpretieren:
- Wenn es heute sonnig ist, liegt die Wahrscheinlichkeit, dass es morgen ebenfalls sonnig ist, bei 80 %. Die Wahrscheinlichkeit für Regen beträgt 20 %. Wenn es heute regnerisch ist, beträgt die Wahrscheinlichkeit für Sonnenschein am nächsten Tag 40 %, während Regen mit 60 % wahrscheinlich ist. Die Zeilen der Übergangsmatrix ergeben korrekterweise jeweils 1.
- An einem sonnigen Tag ist die Wahrscheinlichkeit, dass Ihr Freund glücklich ist, 0,9 beziehungsweise 90 %. Die Wahrscheinlichkeit für Traurigkeit liegt bei 0,1. An einem regnerischen Tag beträgt die Wahrscheinlichkeit für Glücklichsein nur 20 %, während Traurigkeit mit 80 % wahrscheinlicher ist. Auch die Zeilen der Emissionsmatrix summieren sich zu 1.
- Am ersten Tag liegen keine weiteren Informationen vor. Daher wird Sonnig und Regnerisch jeweils dieselbe Anfangswahrscheinlichkeit zugewiesen. Diese Annahme könnte angepasst werden, wenn vorab zusätzliche Informationen verfügbar wären.
Mit diesem HMM lassen sich verschiedene Arten von Fragen beantworten:
- Sequenzwahrscheinlichkeit: Wie wahrscheinlich ist eine bestimmte Abfolge von Stimmungen? Zum Beispiel: Wie wahrscheinlich ist es, dass die Stimmungen über drei Tage [Glücklich, Glücklich, Traurig] waren? Dafür müssen alle möglichen Wettersequenzen aufsummiert werden, die diese Stimmungsfolge erzeugt haben könnten. Der Forward-Algorithmus ermöglicht diese Berechnung effizient in einem Durchlauf.
- Wahrscheinlichste verborgene Sequenz: Wenn eine Beobachtungssequenz von Stimmungen vorliegt, welche Wettersequenz ist dann am wahrscheinlichsten? Zum Beispiel: War bei [Glücklich, Traurig, Glücklich] die Wetterfolge [Sonnig, Regnerisch, Sonnig], [Sonnig, Sonnig, Sonnig] oder eine andere Sequenz wahrscheinlicher? Der Viterbi-Algorithmus berechnet die beste Zustandsfolge, die die Beobachtungen erklärt.
- Lernen aus Daten: Wenn viele beobachtete Sequenzen und möglicherweise teilweise Zustandsinformationen vorliegen, wie lassen sich die HMM-Parameter A, B und π lernen? Der Baum-Welch-Algorithmus, ein Ansatz auf Basis von Erwartungsmaximierung, berechnet Wahrscheinlichkeiten, die die Likelihood der Daten maximieren.
Die Details des Viterbi- und Baum-Welch-Algorithmus werden im nächsten Abschnitt erläutert. Beide gehören zu den wichtigsten Algorithmen für den praktischen Einsatz von HMMs. Der Vollständigkeit halber folgt hier eine kurze Übersicht der drei zentralen Aufgaben, die mit einem HMM gelöst werden können:
- Evaluation: Bei gegebenem Modell wird die Wahrscheinlichkeit einer Beobachtungssequenz berechnet. Dies wird mit dem Forward-Algorithmus gelöst, oder mit dem Forward-Backward-Algorithmus, wenn zusätzlich Rückwärtswahrscheinlichkeiten berechnet werden.
- Decoding: Es wird die einzelne beste Zustandssequenz gesucht, die die Beobachtungen erzeugt haben könnte. Dies wird mit dem Viterbi-Algorithmus gelöst, einer dynamischen Programmierung für den wahrscheinlichsten Pfad.
- Learning: Bei gegebenen Beobachtungssequenzen und eventuell ersten Parameterschätzungen werden Modellparameter gesucht, die die Wahrscheinlichkeit der beobachteten Sequenzen maximieren. Dies wird mit dem Baum-Welch-Algorithmus gelöst, der intern den Forward-Backward-Algorithmus nutzt.
Der Viterbi-Algorithmus: HMMs decodieren
Der Viterbi-Algorithmus ist ein dynamischer Programmieralgorithmus, der für eine gegebene Beobachtungssequenz und ein HMM-Modell die wahrscheinlichste Folge verborgener Zustände berechnet. Er löst das Decoding-Problem. Viterbi-Decoding ist besonders wichtig in Anwendungen, in denen Sequenzdaten wie Spracherkennung oder Part-of-Speech-Tagging durch die wahrscheinlichste zugrunde liegende Zustandsfolge erklärt werden sollen.
Der Algorithmus vermeidet eine brute-forceartige Aufzählung aller möglichen Pfade. Stattdessen durchsucht er die Möglichkeiten effizient, indem er zu jedem Zeitpunkt nur den Pfad mit der höchsten Wahrscheinlichkeit zu jedem Zustand speichert und schrittweise erweitert. Der Viterbi-Algorithmus verwendet daher eine DP-Tabelle viterbi[t][i]. Diese enthält die Wahrscheinlichkeit des wahrscheinlichsten Pfads, der zum Zeitpunkt t im Zustand i endet. In der Praxis wird dieser Wert häufig als Log-Wahrscheinlichkeit gespeichert, um numerische Unterläufe zu vermeiden. Zusätzlich werden Backpointer genutzt, um die tatsächliche Sequenz am Ende zurückzuverfolgen.
Viterbi-DP-Tabelle: Einfache Darstellung
- Das Raster zeigt Zeitschritte von links nach rechts und mögliche Zustände von oben nach unten.
- Die blassen Pfeile verdeutlichen, dass der Algorithmus alle Pfade untersucht, die von einem Zeitschritt zum nächsten führen.
- Der hervorgehobene Pfad zeigt am Ende den einzelnen wahrscheinlichsten Pfad durch die Zustände.
- Der Wert jeder Zelle entspricht dem bisher besten Score für einen Pfad, der zu diesem Zeitpunkt in diesem Zustand endet.
- Backpointer, dargestellt als kleine Markierungen, speichern, welcher Zustand zum jeweiligen besten Score geführt hat. Dadurch kann der Pfad am Ende rückwärts rekonstruiert werden.
Bei t=1 wird mit der Anfangsverteilung und den Emissionswahrscheinlichkeiten initialisiert:
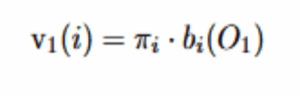
Dies ist die Wahrscheinlichkeit, in Zustand i zu starten und die erste Beobachtung O_1 zu emittieren.
Für jeden folgenden Zeitpunkt t und jeden Zustand j berechnet der Algorithmus:
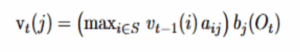
Zum Zeitpunkt t soll der beste Score für das Enden in Zustand j gefunden werden. Das erfolgt in drei Schritten:
- Einen Schritt zurückblicken: Für jeden möglichen vorherigen Zustand i wird der beste Score in i zum Zeitpunkt t−1 genommen und mit der Übergangswahrscheinlichkeit von i nach j multipliziert. So entsteht ein Kandidatenscore für das Erreichen von j aus i.
- Die beste Route auswählen: Aus diesen Kandidatenscores wird der größte Wert gewählt. Das ist der beste Weg, um in j anzukommen, bevor die neue Beobachtung berücksichtigt wird.
- Prüfen, wie gut j die aktuellen Daten erklärt: Der beste Weg wird mit der Wahrscheinlichkeit multipliziert, dass Zustand j die aktuelle Beobachtung erzeugt. Dadurch wird die neue Beobachtung einbezogen und der endgültige Score für Zustand j zum Zeitpunkt t berechnet.
Der Baum-Welch-Algorithmus: HMMs trainieren
Baum-Welch wird eingesetzt, um ein HMM zu trainieren, wenn Beobachtungsdaten vorhanden sind, die Modellparameter jedoch unbekannt sind. Es handelt sich um einen auf HMMs spezialisierten Expectation-Maximization-Algorithmus. Benannt ist er nach Leonard Baum, der ihn gemeinsam mit weiteren Koautoren veröffentlicht hat. Baum-Welch schätzt die Übergangswahrscheinlichkeiten A und Emissionswahrscheinlichkeiten B sowie manchmal auch die Anfangsverteilung π, die die beobachteten Sequenzen am wahrscheinlichsten erzeugt haben.
Der Algorithmus eignet sich, wenn eine Menge von Beobachtungssequenzen vorliegt und angenommen wird, dass diese durch ein HMM mit einer bestimmten Anzahl von Zuständen erzeugt wurden, die konkreten Übergangs- und Emissionswahrscheinlichkeiten aber unbekannt sind. Baum-Welch kann eine lokal optimale Menge von Wahrscheinlichkeiten finden, die die Wahrscheinlichkeit der Daten maximiert.
Funktionsweise des Baum-Welch-Algorithmus
Baum-Welch wechselt iterativ zwischen Erwartung und Maximierung. Im Kern handelt es sich um einen EM-Algorithmus.
Expectation Step
Auf Basis der aktuellen Schätzung der Modellparameter berechnet der Algorithmus die erwartete Anzahl von Übergängen und Emissionen in den Daten. Das geschieht mit dem Forward-Backward-Verfahren:
- Der Forward-Algorithmus berechnet partielle Wahrscheinlichkeiten, meist als α-Werte bezeichnet, für jeden möglichen Zustand zu jedem Zeitpunkt unter Berücksichtigung der Beobachtungen bis zu diesem Punkt.
- Der Backward-Algorithmus berechnet partielle Wahrscheinlichkeiten, die β-Werte, vom aktuellen Zeitpunkt in die Zukunft. Diese fassen die Wahrscheinlichkeit zukünftiger Beobachtungen unter der Annahme eines bestimmten aktuellen Zustands zusammen.
Maximization Step
Im Maximierungsschritt werden die Modellparameter so neu geschätzt, dass sie möglichst gut zu den Daten passen. Grundlage sind die Soft Counts beziehungsweise erwarteten hinreichenden Statistiken aus dem Forward-Backward-Durchlauf. Die Erwartungen können als anteilige Auftretenszahlen verstanden werden. Anschließend werden die Parameter aktualisiert:
- Anfangswahrscheinlichkeiten πi: Normalisierung der erwarteten Anzahl, mit der in Zustand i gestartet wird.
- Übergangswahrscheinlichkeiten a_{ij}: Normalisierung der erwarteten Anzahl von Übergängen i→j für jeden Zustand i.
- Emissionsparameter bj(⋅): Neuschätzung auf Basis der Beobachtungen, gewichtet mit der Wahrscheinlichkeit, sich in Zustand j zu befinden. Bei diskreten Emissionen werden Zählwerte normalisiert; bei Gauß-Verteilungen werden gewichtete Mittelwerte und Kovarianzen aktualisiert.
Kurz gesagt: Zuerst werden im E-Schritt Erwartungen berechnet. Anschließend werden diese erwarteten Zählwerte normalisiert, um aktualisierte Werte für π, A und B zu erhalten.
Hidden Markov Models in Python implementieren
Für die Arbeit mit HMMs stehen in Python mehrere Bibliotheken zur Verfügung. Zwei bekannte Optionen sind:
- hmmlearn: Eine Bibliothek zur Implementierung von HMMs, die sich an den Konventionen von scikit-learn orientiert und einfach zu verwenden ist. Sie bietet leicht nutzbare Klassen für HMMs, darunter diskrete Emissionen über CategoricalHMM und MultinomialHMM sowie Gaußsche Emissionen.
- pomegranate: Eine allgemeinere Bibliothek für probabilistische Modellierung, die ebenfalls HMMs enthält. Sie ist häufig schneller, da intern Cython genutzt wird, und flexibler, da sie diskrete und kontinuierliche Verteilungen sowie benutzerdefinierte Topologien unterstützt.
Beispiel: HMM mit hmmlearn
Im folgenden Beispiel wird das Wetter-Stimmungs-HMM mit hmmlearn umgesetzt. Das Modell wird erstellt, indem die Wahrscheinlichkeitsmatrizen explizit definiert werden. Anschließend wird eine Beobachtungssequenz mit dem Modell decodiert.
pip install hmmlearn
import numpy as np
from hmmlearn import hmm
# Define HMM model with 2 hidden states (Sunny=0, Rainy=1) and 2 observations (Happy=0, Sad=1)
model = hmm.CategoricalHMM(n_components=2, init_params="")
# (init_params="" means we'll manually set startprob, transmat, emissionprob)
model.startprob_ = np.array([0.5, 0.5]) # π: 50% Sunny, 50% Rainy
model.transmat_ = np.array([[0.8, 0.2], # A: Sunny->Sunny 0.8, Sunny->Rainy 0.2
[0.4, 0.6]]) # Rainy->Sunny 0.4, Rainy->Rainy 0.6
model.emissionprob_ = np.array([[0.9, 0.1], # B: Sunny emits Happy 0.9, Sad 0.1
[0.2, 0.8]]) # Rainy emits Happy 0.2, Sad 0.8
# Observation sequence: Friend's moods over 3 days (Happy, Sad, Happy) encoded as [0,1,0]
observations = np.array([[0], [1], [0]])
log_prob, state_sequence = model.decode(observations, algorithm="viterbi")
print(state_sequence) # Most likely hidden state sequence (e.g., [0 1 0])
In diesem Beispiel werden Start-, Übergangs- und Emissionswahrscheinlichkeiten manuell auf die Werte des laufenden Beispiels gesetzt. Die Methode model.decode nutzt den Viterbi-Algorithmus, um für die gegebenen Beobachtungen die wahrscheinlichste Zustandsfolge zu finden. Die Ausgabe state_sequence kann beispielsweise [0 1 0] lauten. Mit den hier verwendeten Bezeichnungen bedeutet das, dass die Wetterfolge Sonnig → Regnerisch → Sonnig war. Der Wert log_prob ist die Log-Likelihood dieser Sequenz unter dem Modell.
Das Argument init_params=““ weist hmmlearn an, die Wahrscheinlichkeiten nicht zufällig zu initialisieren, da sie direkt vorgegeben werden. Wenn Daten vorhanden wären und das HMM von Grund auf trainiert werden sollte, könnte stattdessen model.fit(data) verwendet werden. In diesem Fall würde hmmlearn intern Baum-Welch einsetzen, um die Parameter zu lernen. Dann würde init_params=““ nicht gesetzt, und es wäre entweder eine Startschätzung erforderlich oder eine zufällige Initialisierung möglich.
Anwendungsbereiche von Hidden Markov Models
HMMs werden in vielen Bereichen eingesetzt. Wichtige Beispiele sind:
- Spracherkennung: In der Spracherkennung wurden einige frühe Systeme, etwa IBMs Tangora, eingesetzt, um Audioframes und Phoneme mit HMMs zu modellieren. Die verborgenen Zustände repräsentieren Aussprachevariationen, während die Emissionen das akustische Signal darstellen.
- Bioinformatik: Die Vorhersage von Genen ist ein Beispiel, bei dem verborgene Zustände Klassen von Nukleotiden abbilden können, etwa kodierende oder nicht-kodierende Genregionen. Viele Gen-Vorhersagealgorithmen wie GeneMark und Genscan basieren auf HMMs.
- Finanzen: Eine häufige Anwendung im Finanzbereich ist die Erkennung von Marktregimen, etwa Bullen- oder Bärenmärkten. Dabei sind Volatilitäten und Renditen Emissionen verborgener Faktoren, die den tatsächlichen Zustand der Wirtschaft repräsentieren.
- Zeitreihenprognose: Wenn sich die Dynamik eines Systems in diskreten Zuständen verändert, können HMMs einfachere ARIMA-Modelle übertreffen, indem sie nichtlineare Zustandsübergänge abbilden.
HMMs im modernen Kontext: Über Markov-Modelle hinaus
Die folgende Übersicht zeigt moderne Erweiterungen, die HMMs ergänzen oder ersetzen können.
| Ansatz | Funktionsweise | Unterschied zu HMMs |
|---|---|---|
| Recurrent Neural Networks (RNNs), einschließlich LSTM und GRU | Lernen Sequenzabhängigkeiten, indem Informationen durch rekurrente verborgene Zustände weitergegeben werden. LSTM- und GRU-Architekturen erfassen längere Kontexte durch Gating. | Sie sind nicht auf Markov-Annahmen erster Ordnung beschränkt und können längere Abhängigkeiten erfassen als HMMs. |
| Transformer | Nutzen Self-Attention, um Beziehungen zwischen allen Positionen einer Sequenz zu modellieren. Tief gestapelte Schichten lernen umfangreiche Repräsentationen. | Sie besitzen keine expliziten markovianischen verborgenen Zustände und können die gesamte Sequenz berücksichtigen. In der Regel benötigen sie mehr Daten und Rechenleistung, sind dafür aber sehr ausdrucksstark. |
| Conditional Random Fields (CRFs) | Diskriminative Modelle, die Wahrscheinlichkeiten von Label-Sequenzen direkt aus Beobachtungen für Sequence-Labeling-Aufgaben lernen. | Sie modellieren keinen generativen Prozess für Beobachtungen und liefern bei Labeling-Aufgaben häufig bessere Genauigkeit als HMMs. |
| Hybride Modelle (HMM + NN) | Kombinieren die Struktur von HMMs, etwa Übergänge, mit neuronalen Netzen für Emissionen oder Merkmale. | Sie behalten die interpretierbaren Zustandsübergänge von HMMs bei und nutzen gleichzeitig die Ausdrucksstärke neuronaler Netze für die Modellierung von Beobachtungen. |
Vorteile und Grenzen von Hidden Markov Models
Die folgende Tabelle fasst die wichtigsten Stärken und Schwächen von HMMs zusammen:
| Vorteile | Grenzen |
|---|---|
| Konzeptionelle Einfachheit: HMMs werden durch einfache und interpretierbare Wahrscheinlichkeitsmatrizen definiert. Verborgene Zustände besitzen häufig eine klare Bedeutung. | Markov-Annahme: Der nächste Zustand hängt nur vom vorherigen Zustand ab. Langfristige Abhängigkeiten sind daher schwierig, sofern der Zustandsraum nicht erweitert wird. |
| Effiziente Algorithmen: Decoding und Evaluation können mit Verfahren wie Viterbi und Forward in polynomialer Zeit gelöst werden, wodurch HMMs praktisch einsetzbar bleiben. | Feste Anzahl von Zuständen: Die Anzahl der Zustände muss gewählt werden. Zu wenige Zustände führen zu Underfitting, zu viele zu Overfitting oder schwer handhabbarer Komplexität. |
| Geeignet für kleinere Datenmengen: Mit Fachwissen oder Regularisierung können HMMs auch auf überschaubaren Datensätzen trainiert werden, ohne riesige Datenkorpora zu benötigen. | Unabhängigkeit der Beobachtungen: HMMs nehmen an, dass Beobachtungen bei gegebenem Zustand unabhängig sind. Strukturierte oder zeitliche Korrelationen benötigen Erweiterungen wie HSMMs oder faktorielle HMMs. |
| Probabilistische Inferenz: HMMs liefern Unsicherheitsschätzungen wie Sequenzwahrscheinlichkeiten und Prognosekonfidenzen, die in vielen Szenarien nützlich sind. | Lokale Optima beim Training: Baum-Welch als EM-Verfahren kann in lokalen Optima stecken bleiben, und die Ergebnisse hängen von der Initialisierung ab. |
| Generatives Modell: HMMs können Sequenzen erzeugen und fehlende Daten durch Marginalisierung auf natürliche Weise behandeln. | In vielen Bereichen übertroffen: Moderne RNNs und Transformer liefern häufig höhere Genauigkeit, etwa in der End-to-End-Spracherkennung. Dennoch bleiben HMMs in bestimmten Nischen und in der Lehre relevant. |
FAQ: Hidden Markov Models
Wofür wird ein Hidden Markov Model verwendet?
Es wird verwendet, um sequenzielle Daten probabilistisch zu modellieren, wobei angenommen wird, dass sich ein System Schritt für Schritt weiterentwickelt. HMMs werden häufig in der Spracherkennung, Proteinsequenzanalyse, Finanzmodellierung von Regimen und Anomalieerkennung eingesetzt. Durch das Lernen von Übergängen und Emissionen kann das Modell ableiten, welcher verborgene Zustand am wahrscheinlichsten eine bestimmte Beobachtung erzeugt hat. Dadurch eignen sich HMMs besonders für Probleme, bei denen die Struktur verborgen ist, ihre Auswirkungen aber messbar sind.
Was ist der Unterschied zwischen Markov-Ketten und HMMs?
Eine Markov-Kette modelliert ein System, bei dem der Zustand in jedem Schritt direkt sichtbar ist. Dafür werden nur Zustandsübergangswahrscheinlichkeiten benötigt. HMMs gehen dagegen davon aus, dass der Zustand verborgen ist und nicht direkt beobachtet werden kann.
Stattdessen sieht man Beobachtungen, die aus jedem verborgenen Zustand erzeugt werden. Emissionswahrscheinlichkeiten beschreiben diese Zuordnung. Ein HMM kann daher als „Markov-Kette im Hintergrund“ plus probabilistisches Beobachtungsmodell darüber verstanden werden. Diese zusätzliche Ebene macht HMMs deutlich flexibler für reale Anwendungsfälle.
Wie funktioniert der Viterbi-Algorithmus?
Der Viterbi-Algorithmus findet die wahrscheinlichste Sequenz verborgener Zustände, die eine Sequenz beobachteter Ausgaben erzeugt haben könnte. Dafür nutzt er dynamische Programmierung und vermeidet eine exponentielle brute-forceartige Suche. Zu jedem Zeitpunkt speichert er für jeden verborgenen Zustand den besten Score beziehungsweise die maximale Wahrscheinlichkeit. Anschließend wird der Pfad Schritt für Schritt aufgebaut und die Wahrscheinlichkeiten werden effizient aktualisiert. Am Ende rekonstruiert Backtracking die beste verborgene Zustandsfolge. Dadurch bleibt das Decoding in HMMs auch bei langen Sequenzen rechnerisch praktikabel.
Können HMMs für Zeitreihenprognosen eingesetzt werden?
Ja, HMMs können zukünftige Beobachtungen vorhersagen. Nach dem Training kann das Modell den wahrscheinlichsten nächsten verborgenen Zustand auf Basis der aktuellen Zustandsverteilung schätzen. Aus diesem vorhergesagten Zustand lässt sich anschließend die erwartete Emission beziehungsweise Beobachtung erzeugen. Dadurch liefern HMMs probabilistische Prognosen statt einzelner deterministischer Werte. Besonders nützlich sind sie bei Zeitreihen mit Regimen oder Phasen, zum Beispiel Aufwärts- und Abwärtstrends an Märkten. Daher eignen sich HMMs gut für strukturierte Zeitreihenprognosen mit verborgener Musterdynamik.
Welche modernen Alternativen zu HMMs gibt es?
Conditional Random Fields, RNNs und Transformer sind in der Regel besser geeignet, um komplexe und hochdimensionale Daten zu modellieren als HMMs. Allerdings benötigen sie meist mehr Trainingsdaten und Rechenressourcen.
Fazit
Hidden Markov Models zeigen eindrucksvoll, wie probabilistisches Denken verborgene Strukturen in sequenziellen Daten sichtbar machen kann. Ihre mathematische Klarheit und effizienten Algorithmen haben sie zu einem wichtigen Werkzeug in Bereichen wie Spracherkennung, Bioinformatik, Finanzanalyse und Zeitreihenanalyse gemacht.
Obwohl moderne Deep-Learning-Ansätze wie RNNs, Transformer und hybride Modelle HMMs in vielen Aufgaben übertreffen, funktionieren sie häufig wie Black Boxes. Die Interpretierbarkeit und Einfachheit von HMMs sorgen dafür, dass sie weiterhin ein wertvolles Werkzeug bleiben, um Unsicherheit in dynamischen Systemen zu verstehen und nachvollziehbar zu analysieren.
