
Hidden Markov Models: Theory, Algorithms, Python Implementation, and Modern Alternatives
Hidden Markov Models (HMMs) are probabilistic machine learning models used to identify patterns in sequential data. An HMM assumes that a sequence of hidden states exists beneath the observed data and changes over time. Each hidden state then produces an observable output based on defined emission probabilities.
These models are useful for uncovering hidden structures in changing systems where the actual causes cannot be seen directly and must be inferred from measurable effects. HMMs are especially suited to uncertainty and time-based dependencies in sequence data. This guide explains HMM theory, including transition and emission probability matrices (EM), essential algorithms, Python implementation, and modern alternatives for sequence modeling.
Key Takeaways
HMMs model hidden causes behind observable sequences: They assume an underlying latent Markov process that cannot be observed directly. Instead, it is connected to observations through emission probabilities. This makes HMMs suitable when only the visible effects are available, while the true internal states remain hidden.
Three main problems define how HMMs are used: Evaluation calculates the likelihood of an observation sequence with the Forward algorithm, decoding finds the most likely hidden sequence with the Viterbi algorithm, and learning estimates model parameters with Baum-Welch or EM.
Interpretability is one of their major advantages: Initial probabilities, transition matrices, and emission probabilities all have clear probabilistic meaning. This makes HMMs easier to understand than many deep neural network models.
HMMs are still useful for smaller or structured datasets: They can work well when data is limited or when domain expertise helps define transitions. Common examples include speech recognition, genomics, and financial market regime detection.
Modern deep learning models continue the same idea: RNNs, Transformers, and hybrid HMM-NN models often perform better in large-scale applications. Still, they pursue a similar goal: learning temporal dependencies and representing uncertainty over time.
What Is a Hidden Markov Model?
Hidden Markov Models are probabilistic models for sequence data in which an underlying hidden, or latent, Markov process generates observable outputs. In an HMM, every time step has a hidden state that changes according to Markovian transitions. Each hidden state also has an emission probability that determines which observable symbol or feature is produced.
Markov Chains vs. Hidden Markov Models
A Markov chain is a simpler type of model. It includes states and transition probabilities, but all states are directly observable. For example, if you modeled weather with a Markov chain, the states could be “Sunny” and “Rainy.” In that case, the weather on each day is directly visible. The chain then describes the probability of moving from one weather state today to another weather state tomorrow.
In a Hidden Markov Model, the states cannot be observed directly. Instead, each state generates an observation probabilistically. In the weather example, imagine that you live in a different city and do not know the actual weather in your friend’s city. The weather is the hidden state. However, your friend calls you and tells you how they feel. Each day, you hear observations such as “happy” or “sad,” which give clues about the weather in your friend’s city. The hidden weather affects the observed mood, but the weather itself is never directly observed.
Key Components of a Hidden Markov Model
This section acts as a compact legend for an HMM diagram. It identifies the hidden states, observed symbols, and probability tables π, A, and B. These define the starting probabilities, control transitions, and generate emissions.
Hidden States: At each time step t, the system occupies exactly one latent class s_i. This notation shows that the hidden process is categorical and has N possible regimes. X_t is not directly observed; it must be inferred from the data.
Observations: At every time step, there is one observable symbol or measurement from a finite alphabet. In this setting, the visible data stream is discrete. In practice, O_t is connected to X_t because different hidden states produce different observation patterns.
Initial State Probabilities: The row vector π represents the prior belief about where the sequence begins. Each πi is the probability that the first hidden state is s_i. The normalization condition confirms that this is a valid probability distribution.
Transition Probabilities: The matrix A=[aij] describes state dynamics. It answers the question: if the system is currently in state i, which next states j are likely? The row-stochastic constraint, meaning each row sums to one, ensures every row is a valid conditional distribution. Conditioning on X_t expresses the first-order Markov property: the next state depends only on the current state, not on the full sequence that came before it.
Emission Probabilities: For each hidden state s_i, the row bi(⋅) defines a categorical distribution over observation symbols. If b_i(k) is high, state s_i often emits the observation symbol o_k. This conditional structure connects the unseen process to the observed data.
Sequence Factorization: The product form represents the full generative story. First, choose a starting state using π. Then emit the first observation using B. For each following time step, select the next state using A and emit an observation using B.
Example: Weather and Mood HMM
To make these components easier to understand, consider a simple HMM example. Your friend’s mood depends on the weather in their city. You want to model the system with the following elements:
- Hidden states: The weather in your friend’s city each day. For simplicity, assume two states: Sunny and Rainy.
- Observations: Your friend’s mood each day, either Happy or Sad.
- State transition probabilities: The probability that the weather changes from one day to the next.
- Emission probabilities: The way weather influences mood.
Assume the model is defined as follows:
# HMM Example: Weather and Friend's Mood
States (hidden): [Sunny, Rainy]
Observations: [Happy, Sad]
Transition probability matrix (A):
to Sunny to Rainy
Sunny 0.8 0.2
Rainy 0.4 0.6
Emission probability matrix (B):
Happy Sad
Sunny 0.9 0.1
Rainy 0.2 0.8
Initial state distribution (π):
Sunny: 0.5, Rainy: 0.5
This HMM can be interpreted as follows:
- If today is sunny, there is an 80% probability that tomorrow will also be sunny and a 20% probability that it will be rainy. If today is rainy, there is a 40% probability that tomorrow will be sunny and a 60% probability that it will remain rainy. The rows of the transition matrix correctly add up to 1.
- On a Sunny day, the probability that your friend is Happy is 0.9, or 90%, while the probability of Sad is 0.1. On a Rainy day, the probability of Happy is only 20%, while the probability of Sad is 80%. The rows of the emission matrix also sum to 1.
- For day 1, no prior information is available, so Sunny and Rainy receive equal probability. This could be changed if additional information were known in advance.
With this HMM, several types of questions can be answered:
- Sequence likelihood: What is the probability of a specific mood sequence? For example, what is the probability that over three days the moods were [Happy, Happy, Sad]? This requires summing over all possible weather sequences that could have generated those moods. The Forward algorithm performs this calculation efficiently in one pass.
- Most likely hidden sequence: Given an observation sequence of moods, which weather sequence is most likely? For example, given [Happy, Sad, Happy], was the weather sequence [Sunny, Rainy, Sunny], [Sunny, Sunny, Sunny], or another sequence? The Viterbi algorithm finds the most likely hidden state path that explains the observations.
- Learning from data: If many observed sequences are available, and possibly partial state information, how can the model parameters A, B, and π be learned? The Baum-Welch algorithm, based on expectation-maximization, finds probabilities that maximize the likelihood of the data.
The Viterbi and Baum-Welch algorithms are explained in more detail below. They are the two primary algorithms used to apply HMMs in practice. For completeness, the three main HMM problems are:
- Evaluation: Given a model, compute the probability of an observation sequence. This is solved with the Forward algorithm, or with the Forward-Backward algorithm when backward probabilities are also computed.
- Decoding: Find the single best hidden state path that could have generated the observations. This is solved with the Viterbi algorithm, a dynamic programming approach to finding the maximum-probability path.
- Learning: Given observed sequences and possible initial parameter estimates, find model parameters that maximize the probability of the observations. This is solved with the Baum-Welch algorithm, which uses the Forward-Backward algorithm internally.
The Viterbi Algorithm: Decoding HMMs
The Viterbi algorithm is a dynamic programming method that calculates the most likely hidden state sequence for a given observation sequence and HMM model. It solves the decoding problem. Viterbi decoding is important in applications where sequence data, such as speech recognition or part-of-speech tagging, must be explained by the most likely underlying state sequence.
Viterbi avoids brute-force enumeration of every possible path. At each step, it searches efficiently through the possibilities by keeping only the highest-probability path to each state at each time step. It then builds these paths incrementally. The algorithm stores a dynamic programming table, often written as viterbi[t][i], which represents the probability of the most likely path ending in state i at time t. In practice, this is usually stored as a log-probability to prevent numerical underflow. Backpointers are used to recover the final sequence.
Viterbi DP Table: Simple View
- The grid shows time steps from left to right and possible states from top to bottom.
- Faint arrows indicate that the algorithm explores all paths moving from one time step to the next.
- The bold path eventually represents the single most probable path through the states.
- The value in each cell is the best score found so far for a path ending in that state at that time.
- Backpointers, shown as small annotations, record which previous state produced each best score so the final path can be traced back at the end.
At t=1, initialization uses the initial distribution and emission probabilities:
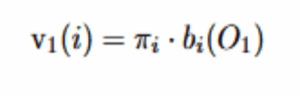
This represents the probability of starting in state i and emitting the first observation O_1.
For every later time t and every state j, the algorithm computes:
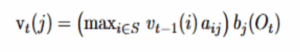
At time t, the goal is to find the best score for ending in state j. This happens in three steps:
- Look back one step: For every possible previous state i, take the best score for i at time t−1 and multiply it by the transition probability from i to j. This produces a candidate score for reaching j from i.
- Choose the best route: Select the largest of those candidate scores. This gives the best way to arrive in j before considering the current observation.
- Evaluate how well j explains the current data: Multiply the best route by the probability that state j emits the current observation. This incorporates the new data and produces the final score for being in j at time t.
The Baum-Welch Algorithm: Training HMMs
Baum-Welch is used to train an HMM when observation data is available but the model parameters are unknown. It is an Expectation-Maximization algorithm specialized for HMMs. The method is named after Leonard Baum and other co-authors who published it. Baum-Welch estimates the transition probabilities A and emission probabilities B, and sometimes the initial distribution π, that most likely generated the observed sequences.
Use Baum-Welch when you have a set of observation sequences and assume that they were produced by an HMM with a certain number of states, but you do not know the exact transition or emission probabilities. The algorithm can find a locally optimal set of probabilities that maximizes the likelihood of the data.
How the Baum-Welch Algorithm Works
Baum-Welch repeatedly alternates between expectation and maximization. In essence, it is an EM algorithm.
Expectation Step
Using the current estimates of the model parameters, the algorithm computes the expected number of transitions and emissions in the data. This is done through the Forward-Backward procedure:
- The Forward algorithm computes partial probabilities, usually called α values, for every possible state at each time, based on the observations up to that point.
- The Backward algorithm computes partial probabilities, called β values, from the current time onward. This summarizes the likelihood of future observations given each possible current state.
Maximization Step
The maximization step re-estimates the model parameters so they fit the data as well as possible, using the soft counts or expected sufficient statistics from the Forward-Backward pass. The expectations can be understood as fractional occurrence counts. Then the parameters are updated:
- Initial state probabilities πi: Normalize the expected count of starting in state i.
- Transition probabilities a_{ij}: Normalize the expected counts of transitions from i to j for each state i.
- Emission parameters bj(⋅): Re-estimate them based on observations weighted by the probability of being in state j. For discrete emissions, normalize counts. For Gaussian emissions, update weighted means and covariances.
In brief: compute expectations in the E-step, then maximize by normalizing the expected counts to produce updated π, A, and B.
Implementing Hidden Markov Models in Python
Several Python libraries are available for working with HMMs. Two common options are:
- hmmlearn: A library that implements HMMs using conventions similar to scikit-learn. It is straightforward to use and includes classes for HMMs with discrete emissions through CategoricalHMM and MultinomialHMM, as well as Gaussian emissions.
- pomegranate: A broader probabilistic modeling library that also includes HMMs. It is often faster because it uses Cython internally and is more flexible because it supports discrete and continuous distributions as well as custom topology.
Example: HMM with hmmlearn
Here is a simple version of the Weather/Mood HMM using hmmlearn. The model is created by explicitly defining the probability matrices. Then an observation sequence is decoded with the model.
pip install hmmlearn
import numpy as np
from hmmlearn import hmm
# Define HMM model with 2 hidden states (Sunny=0, Rainy=1) and 2 observations (Happy=0, Sad=1)
model = hmm.CategoricalHMM(n_components=2, init_params="")
# (init_params="" means we'll manually set startprob, transmat, emissionprob)
model.startprob_ = np.array([0.5, 0.5]) # π: 50% Sunny, 50% Rainy
model.transmat_ = np.array([[0.8, 0.2], # A: Sunny->Sunny 0.8, Sunny->Rainy 0.2
[0.4, 0.6]]) # Rainy->Sunny 0.4, Rainy->Rainy 0.6
model.emissionprob_ = np.array([[0.9, 0.1], # B: Sunny emits Happy 0.9, Sad 0.1
[0.2, 0.8]]) # Rainy emits Happy 0.2, Sad 0.8
# Observation sequence: Friend's moods over 3 days (Happy, Sad, Happy) encoded as [0,1,0]
observations = np.array([[0], [1], [0]])
log_prob, state_sequence = model.decode(observations, algorithm="viterbi")
print(state_sequence) # Most likely hidden state sequence (e.g., [0 1 0])
In this example, the start, transition, and emission probabilities are manually set to match the running example. The model.decode method applies the Viterbi algorithm to identify the most likely sequence of states for the given observations. The state_sequence output may look like [0 1 0]. With the labels used here, that means the weather sequence was Sunny → Rainy → Sunny. The log_prob value is the log-likelihood of that state sequence under the model.
The argument init_params=”” tells hmmlearn not to initialize the probabilities randomly because they are being supplied manually. If you had data and wanted to train the HMM from the beginning, you could instead use model.fit(data). In that case, hmmlearn would use Baum-Welch internally to learn the parameters. You would then avoid setting init_params=”” and either provide an initial estimate or allow random initialization.
Applications of Hidden Markov Models
HMMs have been used in many different fields. Important examples include:
- Speech Recognition: In speech recognition, early systems such as IBM’s Tangora used HMMs to model audio frames and phonemes. Hidden states represented pronunciation variation, while emissions represented the acoustic signal.
- Bioinformatics: Gene prediction is an example where hidden states can represent nucleotide classes, such as coding or non-coding gene regions. Many gene prediction algorithms, including GeneMark and Genscan, are based on HMMs.
- Finance: A common financial application is detecting market regimes, such as bull or bear markets. In this case, volatility and returns are emissions from hidden factors that represent the underlying state of the economy.
- Time-Series Prediction: When system dynamics change in discrete regimes, HMMs can outperform simpler ARIMA models by representing non-linear state transitions.
HMMs in a Modern Context: Beyond Markov Models
The following overview summarizes modern extensions that can complement or replace HMMs.
| Approach | How It Works | Contrast with HMMs |
|---|---|---|
| Recurrent Neural Networks (RNNs), including LSTM and GRU | Learn sequence dependencies by passing information through recurrent hidden states. LSTM and GRU architectures handle long-range context through gating. | They are not restricted to first-order Markov assumptions and can capture longer dependencies than HMMs. |
| Transformers | Use self-attention to model relationships across every position in a sequence. Deep stacked layers learn rich representations. | They do not rely on explicit Markovian hidden states and can attend to the full sequence. They usually require more data and compute but are highly expressive. |
| Conditional Random Fields (CRFs) | Discriminative models that directly learn probabilities of label sequences given observations for sequence labeling tasks. | They do not model a generative process for observations and often achieve better labeling accuracy than HMMs. |
| Hybrid Models (HMM + NN) | Combine HMM structure, such as transitions, with neural networks for emissions or feature modeling. | They preserve the interpretable transition structure of HMMs while using neural networks for more expressive observation modeling. |
Advantages and Limitations of Hidden Markov Models
The following table summarizes the main strengths and weaknesses of HMMs:
| Advantages | Limitations |
|---|---|
| Conceptual Simplicity: HMMs are defined by clear and interpretable probability matrices, and hidden states often have meaningful semantics. | Markov Assumption: The next state depends only on the previous state, so long-range dependencies are difficult unless the state space is expanded. |
| Efficient Algorithms: Decoding and evaluation can be solved in polynomial time with methods such as Viterbi and Forward, making HMMs practical. | Fixed Number of States: The number of states must be selected in advance. Too few states can underfit, while too many can overfit or become difficult to manage. |
| Works with Small Data: With domain knowledge or regularization, HMMs can be trained on modest datasets without requiring huge corpora. | Observation Independence: HMMs assume observations are independent given the state. Structured or temporal correlations require extensions such as HSMMs or factorial HMMs. |
| Probabilistic Inference: HMMs provide uncertainty estimates, including sequence likelihoods and prediction confidence, which are useful in many settings. | Local Optima in Training: Baum-Welch, as an EM method, can get stuck in local optima, and results depend on initialization. |
| Generative Model: HMMs can generate sequences and naturally handle missing data through marginalization. | Outperformed in Many Areas: Modern RNNs and Transformers often achieve higher accuracy, such as in end-to-end speech recognition, although HMMs remain valuable in specific niches and education. |
FAQ: Hidden Markov Models
What Is a Hidden Markov Model Used For?
It is used to model sequential data probabilistically and assumes that the system evolves step by step. HMMs are widely used in speech recognition, protein sequence analysis, finance for regime modeling, and anomaly detection. By learning transitions and emissions, the model can infer which hidden state most likely produced each observation. This makes HMMs useful for problems where the underlying structure is hidden, but its effects can be measured.
What Is the Difference Between Markov Chains and HMMs?
A Markov chain describes a system where the state at each step is directly visible. Only state transition probabilities are needed. HMMs, by contrast, assume that the state is hidden and cannot be observed directly.
Instead, observations are generated from each hidden state, and emission probabilities describe this connection. An HMM can therefore be understood as a Markov chain underneath, combined with a probabilistic observation model on top. This additional layer makes HMMs much more flexible for real-world applications.
How Does the Viterbi Algorithm Work?
The Viterbi algorithm finds the most probable hidden state sequence that could have produced a sequence of observations. It uses dynamic programming to avoid an exponential brute-force search. At each time step, it stores the best score, or maximum probability, for every hidden state. It then builds the path step by step and updates probabilities efficiently. At the end, backtracking reconstructs the best hidden state sequence. This makes HMM decoding computationally practical even for long sequences.
Can HMMs Be Used for Time-Series Forecasting?
Yes, HMMs can be used to predict future observations. After training, the model can estimate the most likely next hidden state based on the current state distribution. From that predicted hidden state, it can generate the expected emission or observation. This allows HMMs to produce probabilistic forecasts instead of single deterministic values. They are especially useful for time series with regimes or phases, such as market uptrends and downtrends. Therefore, HMMs are effective for structured time-series forecasting where hidden pattern dynamics matter.
What Are Modern Alternatives to HMMs?
Conditional Random Fields, RNNs, and Transformers are generally stronger for modeling complex and high-dimensional data than HMMs, but they usually need more training data and computing resources.
Conclusion
Hidden Markov Models are a strong example of how probabilistic reasoning can reveal structure in sequential data. Their mathematical clarity and efficient algorithms have made them important in fields such as speech recognition, bioinformatics, finance, and time-series analysis.
Although modern deep learning approaches, including RNNs, Transformers, and hybrid models, have surpassed HMMs in many tasks, they often behave like black boxes. The interpretability and simplicity of HMMs ensure that they remain useful for understanding and reasoning about uncertainty in dynamic systems.
