
Ridge Regression: Regularisierung zur Reduzierung von Overfitting im Machine Learning
Das Ziel des Machine Learning besteht darin, Modelle zu entwickeln, die auch für Daten zuverlässige Vorhersagen liefern können, die sie während des Trainings nie gesehen haben. Eine der größten Herausforderungen dabei ist das sogenannte Overfitting: Ein Modell erzielt zwar hervorragende Ergebnisse auf den Trainingsdaten, versagt jedoch häufig bei neuen, unbekannten Datensätzen. Ridge Regression begegnet diesem Problem durch Regularisierung, indem sie große Koeffizienten über einen zusätzlichen Strafterm begrenzt und so die Generalisierungsfähigkeit des Modells verbessert.
Dieser Leitfaden bietet eine umfassende Einführung in die Ridge Regression. Zunächst werden die grundlegenden Konzepte und die Motivation hinter dem Verfahren erläutert. Anschließend werden die mathematischen Grundlagen vorgestellt und mit verwandten Regularisierungsmethoden wie Lasso und ElasticNet verglichen. Darüber hinaus lernst du, wie sich Ridge Regression in Python implementieren lässt. Abschließend behandelt der Leitfaden bewährte Vorgehensweisen sowie typische Anwendungsfälle, in denen Ridge Regression in der Praxis besonders vorteilhaft ist.
Voraussetzungen
- Sicherer Umgang mit Matrizen, Eigenwerten und grundlegenden Optimierungskonzepten, einschließlich der Interpretation einer Kostenfunktion.
- Verständnis dafür, wie Overfitting die Modellleistung verschlechtert und warum Regularisierung (Strafterm-Ansätze wie L2) zur Kontrolle eingesetzt wird.
- Fähigkeit, mit Python-Bibliotheken wie NumPy, pandas und scikit-learn zu arbeiten, einschließlich Datenvorverarbeitung und Modellbewertung.
- Kenntnisse zu Train/Test-Splitting, Cross-Validation, Hyperparameter-Tuning sowie gängigen Metriken wie R² und RMSE.
- Grundverständnis für das Anpassen einer Linie/Hyperebene und die Ordinary-Least-Squares-Methode.
Was ist Ridge Regression?
Ridge Regression erweitert die lineare Regression durch Ridge-Regularisierung. In der klassischen linearen Regression besteht das Hauptziel darin, eine Hyperebene (oder eine Linie bei zweidimensionalen Daten) zu finden, die die gesamte Summe der quadrierten Fehler zwischen beobachteten und vorhergesagten Werten minimiert.
Sum of Squared Errors,
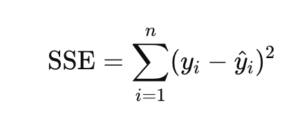
yi steht für den tatsächlichen Wert der abhängigen Variable, während ŷi den jeweiligen Vorhersagewert beschreibt. Wenn sehr viele Prädiktoren vorhanden sind oder starke Multikollinearität zwischen Features besteht, steigt die Wahrscheinlichkeit für Overfitting. In solchen Fällen können Koeffizienten extrem groß werden, sodass das Modell eher Rauschen und zufällige Schwankungen lernt als die echten Zusammenhänge in den Daten.
Wie funktioniert Ridge Regression?
Ridge Regression begrenzt die Größenordnung der Koeffizienten, indem sie zur Summe der quadrierten Fehler einen Strafterm hinzufügt:
Cost Function for Ridge,
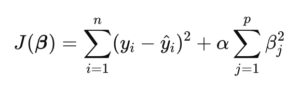
Hier:
- βj bezeichnet die Parameter bzw. Koeffizienten.
- Der Regularisierungsparameter α bestimmt, wie stark der Strafterm im Ridge-Regression-Modell wirkt.
- p ist die Gesamtzahl der Parameter im Modell.
Die klassische lineare Regression berechnet ihre Koeffizienten, indem sie die Normalgleichung löst,
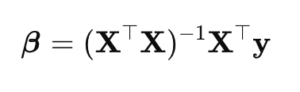
- β ist der Koeffizientenvektor.
- Xᵀ ist die Transponierte der Matrix X.
- (XᵀX)⁻¹ ist die Inverse des Produkts aus Xᵀ und X.
- y ist der Zielvektor.
Ridge Regression passt diesen Ansatz an, indem sie einen Strafterm – konkret I – zur Matrix XᵀX addiert,
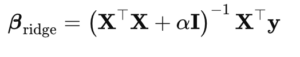
Zentrale Erkenntnisse
- Shrinkage: Wird αI zu XᵀX addiert, sind die Eigenwerte von XᵀX + αI größer oder gleich denen von XᵀX. Dadurch lässt sich die Matrix stabiler invertieren, was übergroße Koeffizientenschätzungen besser verhindert.
- Bias-Variance Trade-off: Durch das Schrumpfen der Koeffizienten steigt der Bias leicht, während die Varianz deutlich sinkt. Dieses Gleichgewicht kann die Leistung auf neuen, unbekannten Daten spürbar verbessern.
- Hyperparameter α: α steuert die Intensität der Regularisierung. Ist α zu groß, können Koeffizienten zu stark reduziert werden, was Underfitting begünstigt. Ist α zu klein, bleibt der Regularisierungseffekt fast aus und das Modell kann überfitten, ähnlich wie eine gewöhnliche lineare Regression.
Praktische Hinweise für den Einsatz
Gute Ergebnisse mit Ridge Regression im Praxisbetrieb hängen von sauberer Datenaufbereitung, sinnvollem Hyperparameter-Tuning und einer sorgfältigen Interpretation des Modellverhaltens ab.
Daten-Skalierung und Normalisierung
Ein typischer Fehler besteht darin, Skalierung oder Normalisierung der Features zu vernachlässigen. Ridge Regression bestraft große Koeffizienten, um Overfitting zu reduzieren. Liegen Features jedoch auf sehr unterschiedlichen Skalen, kann der Strafterm ungleich wirken. Dann werden Koeffizienten großer Skalen oft stärker geschrumpft als jene kleiner Skalen, was verzerrte und schwer vorhersagbare Resultate begünstigt.
Durch Standardisierung oder Normalisierung wird sichergestellt, dass jedes Feature einen vergleichbaren Beitrag zum Strafterm leistet. Wenn Features auf ähnlichen Skalen liegen, kann Ridge Regression die Strafe konsistenter über alle Koeffizienten hinweg anwenden, was Zuverlässigkeit und Modellperformance verbessert. Deshalb gilt: Vor dem Einsatz von Ridge Regression sollten Daten idealerweise standardisiert oder normalisiert werden.
Hyperparameter-Tuning
Cross-Validation ist der Standardweg, um den besten α-Wert zu bestimmen, der die Regularisierungsstärke festlegt. Üblicherweise wird eine Bandbreite an Alpha-Werten getestet – oft logarithmisch verteilt –, das Modell trainiert, die Validierungsleistung geprüft und anschließend der Wert gewählt, der die besten Ergebnisse liefert.
Interpretierbarkeit vs. Performance
Ridge Regression kann die Interpretierbarkeit erschweren, weil sie nicht automatisch Features entfernt. Die Koeffizienten werden zwar verkleinert, bleiben aber im Modell enthalten. Wenn Interpretierbarkeit besonders wichtig ist und viele Features irrelevant sind, sollte Ridge mit Lasso oder ElasticNet verglichen werden.
Fehlinterpretationen vermeiden
Eine verbreitete Fehlannahme ist, Ridge Regression als direktes Feature-Selection-Verfahren zu verstehen. Ridge kann zwar zeigen, welche Features stärker wirken, weil manche Koeffizienten weniger schrumpfen als andere, sie setzt jedoch keine Koeffizienten exakt auf null. Wenn ein Modell gezielt nur einen Teil der Features betonen soll, können Lasso oder ElasticNet besser geeignet sein.
Ridge-Regression-Beispiel und Implementierung in Python
Das folgende Beispiel zeigt, wie Ridge Regression mit scikit-learn umgesetzt wird. Stell dir ein Datenset zu Immobilienpreisen vor – mit Merkmalen wie Hausgröße, Anzahl der Schlafzimmer, Alter und Kennzahlen zur Lage. Ziel ist es, den Preis vorherzusagen. Außerdem vermuten wir, dass einige Features korreliert sind (zum Beispiel Hausgröße und Schlafzimmeranzahl).
Import der benötigten Bibliotheken
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Ridge
from sklearn.metrics import r2_score, mean_squared_error
Datensatz laden
In einer sauberen Tabellenstruktur sind die Features spaltenweise abgelegt, während das Ziel (Preis) in einer eigenen Spalte geführt wird. Die synthetischen Daten orientieren sich an realistischen Mustern aus der Praxis (etwa am Zusammenhang zwischen Hausgröße und Schlafzimmeranzahl).
# --- synthetic--but you could load a real CSV here ---
np.random.seed(42)
n_samples = 200
df = pd.DataFrame({
"size": np.random.randint(500, 2500, n_samples),
"bedrooms": np.random.randint(1, 6, n_samples),
"age": np.random.randint(1, 50, n_samples),
"location_score": np.random.randint(1, 10, n_samples)
})
# price formula with some noise
df["price"] = (
df["size"] * 200
+ df["bedrooms"] * 10000
- df["age"] * 500
+ df["location_score"] * 3000
+ np.random.normal(0, 15000, n_samples) # ← noise
)
Features und Zielvariable trennen
Die Trennung von Prädiktoren (X) und Ziel (y) macht klar, was das Modell lernen soll.
X = df.drop("price", axis=1).values
y = df["price"].values
Train-Test-Split
Wenn 20 % der Daten für die finale Bewertung zurückgehalten werden, lässt sich die Generalisierungsfähigkeit realistisch einschätzen.
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
Features standardisieren
Die L2-Strafe in Ridge basiert auf der quadrierten Größe der Koeffizienten. Skalierung verhindert, dass Features mit großen Zahlenbereichen den Strafterm dominieren.
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
Hyperparameter-Grid für α (Regularisierungsstärke) definieren
Die Funktion np.logspace(-2, 3, 20) erzeugt 20 α-Werte (Regularisierungsstärken), die logarithmisch zwischen 10-2 (0.01) und 103 (1000) verteilt sind. Dieses Log-Grid ermöglicht es, sowohl schwache als auch starke Regularisierung sinnvoll zu prüfen.
param_grid = {"alpha": np.logspace(-2, 3, 20)} # 0.01 → 1000
ridge = Ridge()
Grid-Search mit Cross-Validation durchführen
Cross-Validation hilft, Bias und Varianz sinnvoll auszubalancieren, und reduziert das Risiko, ein Modell nur wegen eines glücklichen Train-Test-Splits auszuwählen.
grid = GridSearchCV(
ridge,
param_grid,
cv=5, # 5-fold CV
scoring="neg_mean_squared_error",
n_jobs=-1
)
grid.fit(X_train_scaled, y_train)
print("Best α:", grid.best_params_["alpha"])
Output: Best α: 0.01
Da die Datenqualität bereits sehr gut war, reichte eine geringe Regularisierung aus. So wurden die Vorhersagen stabiler, ohne das Modell zu stark zu vereinfachen oder die Koeffizienten übermäßig zu reduzieren.
Ausgewählter Ridge-Estimator
best_ridge = grid.best_estimator_
best_ridge.fit(X_train_scaled, y_train)
Modell auf unbekannten Daten bewerten
Im folgenden Code zeigt R², wie viel Varianz das Modell auf neuen, unbekannten Beispielen erklärt. RMSE beschreibt die typische Abweichung zwischen vorhergesagten und tatsächlichen Immobilienpreisen – gemessen in denselben Währungseinheiten.
y_pred = best_ridge.predict(X_test_scaled)
r2 = r2_score(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred) # returns MSE
rmse = np.sqrt(mse) # take square root
print(f"Test R² : {r2:0.3f}")
print(f"Test RMSE: {rmse:,.0f}")
Output: Test R² : 0.988 Test RMSE: 14,229
Ein Test-R² von 0.988 bedeutet, dass das Modell 98.8 % der Preisvariation bei unbekannten Häusern erklärt. Damit erfassen die verwendeten Features nahezu alle relevanten Preisschwankungen.
Ein RMSE von $14,000 deutet darauf hin, dass die Vorhersagen im Mittel etwa $14,000 vom tatsächlichen Preis abweichen.
Koeffizienten prüfen
Wenn man die geschrumpften, aber nicht auf null gesetzten Koeffizienten betrachtet, erkennt man, welche Variablen den Hauspreis beeinflussen, und bestätigt zugleich, dass kein Feature entfernt wurde.
coef_df = pd.DataFrame({
"Feature": df.drop("price", axis=1).columns,
"Coefficient": best_ridge.coef_
}).sort_values("Coefficient", key=abs, ascending=False)
print(coef_df)
Output:
| Merkmal | Koeffizient |
|---|---|
Größe (size) |
107.713,283911 |
Schlafzimmer (bedrooms) |
14.358,773012 |
Alter (age) |
-8.595,556581 |
Standortbewertung (location_score) |
5.874,461993 |
Die Koeffizienten deuten darauf hin, dass die Größe der stärkste Treiber für den Immobilienwert ist: Größere Häuser gewinnen pro standardisierter Einheit etwa $108,000 hinzu. Jedes zusätzliche Schlafzimmer steigert den Wert um ungefähr $14,000. Mit zunehmendem Alter sinkt der Wert um rund $8,600 pro Jahr. Eine Erhöhung des Location Scores um einen Punkt erhöht den prognostizierten Preis um etwa $5,874.
Vorteile und Nachteile der Ridge Regression
Die folgende Tabelle fasst die wichtigsten Stärken und Grenzen von Ridge Regression zusammen.
| Vorteile | Nachteile | Kurzfazit |
|---|---|---|
| Reduziert Overfitting – die L2-Strafe verkleinert große Koeffizienten, senkt die Varianz und verbessert die Generalisierung. | Keine integrierte Feature-Auswahl – Koeffizienten werden nie exakt null, daher bleibt das Modell dicht besetzt. | Wähle Ridge, wenn alle Prädiktoren erhalten bleiben sollen, aber ihr Einfluss begrenzt werden muss. |
| Umgang mit Multikollinearität – stabilisiert Schätzungen, wenn Prädiktoren stark miteinander korrelieren. | Hyperparameter-Tuning erforderlich – der beste α-Wert wird typischerweise per Cross-Validation ermittelt, was zusätzlichen Rechenaufwand verursachen kann. | Plane Zeit für ein CV-Grid oder eine Suche über verschiedene α-Werte ein. |
| Effizient berechenbar – bietet eine geschlossene Lösung und schnelle, etablierte Implementierungen in scikit-learn. | Weniger interpretierbar – alle Features bleiben im Modell, wenn auch abgeschwächt, wodurch Koeffizienten schwerer lesbar sind als bei sparsamen Lasso-Modellen. | Kombiniere Ridge mit Feature-Importance-Visualisierungen oder SHAP, um die Verständlichkeit zu verbessern. |
| Erhält kontinuierliche Koeffizienten – nützlich, wenn mehrere Features gemeinsam das Ergebnis beeinflussen und keines vollständig entfernt werden sollte. | Fügt Bias hinzu, wenn α zu hoch ist – zu starke Schrumpfung kann zu Underfitting und Signalverlust führen. | Beobachte den Validierungsfehler bei steigendem α und stoppe, bevor die Performance nachlässt. |
Nutze die obigen Hinweise als schnelle Orientierung, um zu entscheiden, ob Ridge Regression die passende Regularisierungsmethode für dein Projekt ist.
Ridge Regression vs. Lasso vs. ElasticNet
Bei Regularisierung im Machine Learning stehen meist drei Verfahren im Mittelpunkt: Ridge Regression, Lasso Regression und ElasticNet. Alle verfolgen das gleiche Ziel, Overfitting durch Strafmechanismen für große Koeffizienten zu begrenzen, unterscheiden sich aber darin, wie diese Strafen wirken und wie Koeffizienten behandelt werden.
| Aspekt | Ridge Regression | Lasso Regression | Elastic Net |
|---|---|---|---|
| Strafterm (Penalty) | L2 (Summe der quadrierten Koeffizienten) | L1 (Summe der absoluten Koeffizienten) | Kombination aus L1- und L2-Regularisierung |
| Einfluss auf Koeffizienten | Verkleinert alle Koeffizienten; keiner wird exakt auf 0 gesetzt | Setzt einige Koeffizienten exakt auf 0 (Feature-Selektion) | Setzt einige Koeffizienten auf 0 und verkleinert andere |
| Feature-Selektion | Nein | Ja | Ja |
| Am besten geeignet für | Viele Prädiktoren und Multikollinearität | Hochdimensionale Datensätze mit wenigen relevanten Variablen | Korrelierte Prädiktoren, bei denen sowohl Schrumpfung als auch Selektion erforderlich sind |
| Umgang mit korrelierten Features | Verteilt die Gewichte auf korrelierte Variablen | Behält oft eine Variable bei und verwirft die übrigen | Kann Gruppen korrelierter Variablen gemeinsam beibehalten |
| Interpretierbarkeit | Geringer, da alle Features im Modell verbleiben | Höher, da das Modell sparsamer und übersichtlicher ist | Mittel |
| Hyperparameter | λ (Regularisierungsstärke) | λ (Regularisierungsstärke) | λ (Gesamtstärke), α (Mischungsverhältnis von L1 und L2) |
| Typische Anwendungsfälle | Preisprognosen mit vielen korrelierten Eingangsvariablen | Genselektion, Textklassifikation | Genomik, Finanzwesen und Datensätze mit korrelierten Prädiktoren |
| Einschränkungen | Führt keine Feature-Selektion durch | Kann bei stark korrelierten Prädiktoren instabil werden | Erfordert die Abstimmung von zwei Hyperparametern |
Welche Methode geeignet ist – Ridge, Lasso oder ElasticNet – hängt von der Datenstruktur und den Anforderungen der Aufgabe ab. Ridge Regression passt besonders gut, wenn Prädiktoren korreliert sind und das Entfernen von Koeffizienten nicht erforderlich ist. Lasso ist sinnvoll, wenn irrelevante Features gezielt entfernt werden sollen. ElasticNet kombiniert beide Ansätze und bietet eine ausgewogene Zwischenlösung.
Anwendungsbereiche der Ridge Regression
Ridge Regression liefert in vielen Branchen stabile und präzise Vorhersagen, vor allem bei komplexen oder hochdimensionalen Datensätzen. Beispiele für typische Anwendungen:
- Finance and Economics: Aufgaben wie Portfolio-Optimierung und Risikoanalyse brauchen kontrollierte Koeffizientenschätzungen, um Stabilität sicherzustellen.
- Healthcare: Diagnostikmodelle sind anfällig für Overfitting und instabile Koeffizienten; Ridge Regression kann hier Stabilität schaffen.
- Marketing and Demand Forecasting: Bei der Vorhersage von Sales oder Click-through-Rates müssen oft viele, stark korrelierte Features analysiert werden; Ridge Regression kann Multikollinearität sinnvoll abfedern.
- Natural Language Processing: In Textklassifikation und Sentiment Analysis mit tausenden Features (Wörter und n-grams) kann Ridge Overfitting auf irrelevante Begriffe reduzieren und korrelierte Prädiktoren besser handhaben.
FAQ SECTION
Q1. What is Ridge regression?
Ridge regression ist eine Form linearer Regularisierung, die einen L2-Strafterm einsetzt, bei dem Koeffizienten quadriert werden, um Multikollinearität zu adressieren und Overfitting zu reduzieren.
How does Ridge regression prevent overfitting?
Indem große Gewichte bestraft werden, tauscht das Modell einen kleinen Bias-Anstieg gegen eine starke Varianzreduktion ein und generalisiert dadurch besser.
What is the difference between Ridge and Lasso Regression?
Ridge Regression (L2) schrumpft Koeffizienten, um Overfitting zu begrenzen, während Lasso Regression (L1) einige Koeffizienten exakt auf null setzt und damit Feature Selection betreibt.
When should I use Ridge Regression over other models?
Wähle Ridge Regression bei Datensätzen mit vielen korrelierten Features, bei denen sich das Signal auf mehrere Variablen verteilt und stabile Schätzungen wichtiger sind als ein spärliches Modell.
Can Ridge Regression perform feature selection?
Nein. Ridge Regression reduziert die Größenordnung der Variablen, eliminiert sie jedoch nicht.
How do I implement Ridge Regression in Python?
Ridge Regression lässt sich mit scikit-learn umsetzen. Starte mit dem Import der Ridge-Klasse: from sklearn.linear_model import Ridge.
Erstelle ein Modell, zum Beispiel: model = Ridge(alpha=1.0). Damit wird Ridge Regression mit einem Alpha-Wert von 1.0 als Regularisierungsstärke initialisiert.
Trainiere es mit model.fit(X_train, y_train) und erzeuge Vorhersagen über model.predict(X_test).
Scikit-learn’s Ridge verarbeitet die L2-Strafe intern automatisch.
Für Klassifikationsaufgaben kannst du LogisticRegression mit penalty=’l2′ verwenden.
Fazit
Ridge Regression bietet einen verlässlichen Ansatz, um Overfitting zu reduzieren – besonders bei Datensätzen mit Multikollinearität oder sehr vielen Features. Der L2-Strafterm stabilisiert die Koeffizientenschätzungen und behält zugleich alle Features bei, wodurch ein Gleichgewicht zwischen Bias und Varianz erhalten bleibt.
Durch passende Datenvorverarbeitung, sorgfältiges Hyperparameter-Tuning und eine durchdachte Interpretation verbessert Ridge Regression die Performance in verschiedenen Bereichen, darunter Finance, Healthcare, Marketing und NLP.
Wer versteht, wann und wie Ridge Regression im Vergleich zu Lasso und ElasticNet eingesetzt wird, kann die Genauigkeit und Robustheit von Machine-Learning-Modellen langfristig besser sichern.
