
Entwurf von hardwarebewussten Algorithmen: FlashAttention
Das „T“ in chatGPT steht für Transformer, die Schlüsselarchitektur moderner KI-Entwicklung. Ursprünglich entwickelten Forscher den Transformer für maschinelle Übersetzung. Diese Architektur führte die Selbstaufmerksamkeit ein, wie im Papier Attention is all you need beschrieben. Über Schichten miteinander verbundener Knoten entsteht eine mathematische Darstellung, die Beziehungen und Relevanzen identifiziert, um eine Eingabesequenz in eine Ausgabesequenz zu transformieren.
Wenn Aufmerksamkeit alles ist, was Sie brauchen, machen wir es besser…
Die Transformer-Architektur hat eine neue Ära der KI-Forschung eingeleitet. Diese Forschung steigert die Effizienz des Kernmechanismus, der Aufmerksamkeit. Da die Zeit- und Speicherkomplexität der Aufmerksamkeit quadratisch (O(n²)) mit der Sequenzlänge (n) skaliert, erschwert sie die Modellierung langer Sequenzen. Lange Texte, Codebasen oder hochauflösende Bilder erfordern jedoch, dass Algorithmen Abhängigkeiten über große Distanzen erfassen. Um diese Herausforderung zu lösen, entwickelten Forscher hardwarebewusste und speichereffiziente Algorithmen wie FlashAttention.
Einleitung
Dieser Artikel zeigt die Konzepte, die FlashAttention (2022) erfolgreich gemacht haben. Die Techniken der zweiten (2023) und dritten (2024) Iteration behandeln wir in späteren Beiträgen.
Voraussetzungen
Folgende Kenntnisse erleichtern das Verständnis der Themen dieses Artikels:
- Der Transformer und der Aufmerksamkeitsmechanismus
- Matrizenmultiplikation
- Softmax-Operation
- Vorwärts-/Rückwärtsausbreitung (Forward-/Backward-Pass)
- Die GPU-Speicherhierarchie
- GPU-Leistungsoptimierung
- CUDA-Programmierungskonzepte (Thread-Blocks, Warps, Kerne)
- Gleitpunktformate (FP16, BF16, FP8)
Entwurf von hardwarebewussten und speichereffizienten Algorithmen
Moderne GPUs wie Hopper und Ampere bieten eine enorme Anzahl an Gleitpunktoperationen pro Sekunde (FLOPS), die ihre theoretische Rechenleistung darstellen. Gleichzeitig begrenzt jedoch die Speicherbandbreite die Geschwindigkeit, mit der Daten zwischen dem GPU-Speicher und den Verarbeitungseinheiten übertragen werden. Forscher entwerfen hardwarebewusste und speichereffiziente Algorithmen, indem sie die Speicherhierarchie optimal ausnutzen und möglichst viele der theoretischen FLOPS verwenden.
FlashAttention ist ein Paradebeispiel für einen Algorithmus, der längere Kontexte in Transformern ermöglicht. Er optimiert den Aufmerksamkeitsmechanismus für die zugrunde liegende Hardware.
FlashAttention (2022)
FlashAttention reduziert die Anzahl der Lese-/Schreibvorgänge zwischen GPU-Hochgeschwindigkeitsspeicher (HBM) und GPU-On-Chip-SRAM durch Tiling. Die Forscher beschreiben ihn als einen „IO-bewussten genauen Aufmerksamkeitsalgorithmus“.
GPU-Speicher: HBM & SRAM
Begriffe rund um GPU-Speichertypen variieren, obwohl sie oft ähnliche Konzepte beschreiben. FlashAttention nutzt zwei Speichertypen: HBM und SRAM.
| Speicher | AKA | Hauptmerkmale |
|---|---|---|
| HBM (High Bandwidth Memory) | GPU-Speicher, globaler Speicher | Langsam, große Speicherkapazität |
| SRAM (Static Random-Access Memory) | L1-Cache, Shared Memory | Schnell, kleine Speicherkapazität, On-Chip |
GPU-Computemodell
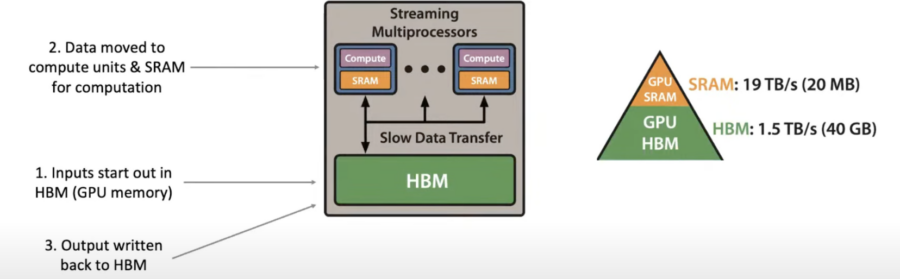
Diagramm aus dem YouTube-Video von Aleksa Gordić mit FlashAttention-Autor Tri Dao: Streaming-Multiprozessoren (2) sind blau dargestellt und enthalten Recheneinheiten sowie SRAM. Globale Speicherzugriffe von und zu HBM sind langsam und sollten nach Möglichkeit minimiert werden.
Es lohnt sich, ein Verständnis dafür zu entwickeln, wie Daten in der GPU übertragen werden.
- Eingaben beginnen im HBM (GPU-Speicher)
- Daten werden für die Berechnung in Recheneinheiten und SRAM verschoben
- Ausgabe wird zurück in das HBM geschrieben
Aufmerksamkeitsberechnung
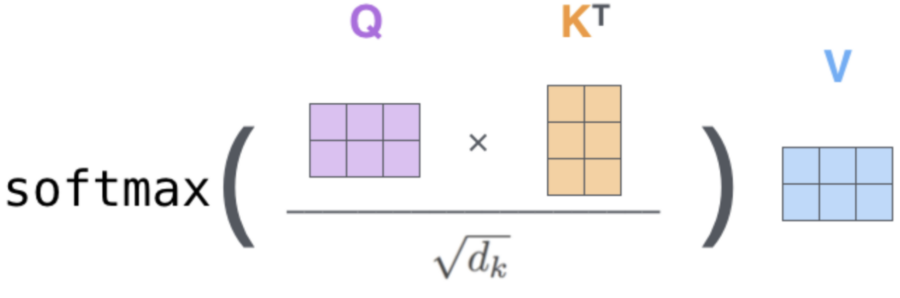
Die Aufmerksamkeitsaufstellung
Eine Auffrischung der Variablen zur Berechnung der Selbstaufmerksamkeitsschicht im Transformer:
- Abfrage (Q): Der Abfragevektor ist die aktuelle Eingabe oder das Element, für das die Aufmerksamkeit berechnet wird. Er gehört zu einer Matrix der Größe Nxd, wobei N die Sequenzlänge und d die Kopfdimension darstellt.
- Schlüssel (K): Die Schlüsselmatrix hat dieselben Dimensionen wie die Abfragematrix. Die Multiplikation von Abfrage- und Schlüsselvektoren ergibt Ähnlichkeitswerte.
- Ähnlichkeitswert (S): S misst, wie ähnlich die Abfrage jedem Element in der Sequenz ist. Die Multiplikation der Abfragematrix mit der transponierten Schlüsselmatrix liefert eine NxN-Matrix der Ähnlichkeitswerte.
- Aufmerksamkeitswahrscheinlichkeit (P): Die Softmax-Operation normalisiert S und erzeugt Wahrscheinlichkeiten, die sich zu 1 summieren.
- Wert (V): Die Wertvektoren enthalten Informationen über jedes Element und multiplizieren sich mit den Wahrscheinlichkeiten, um die Ausgabe zu erzeugen.

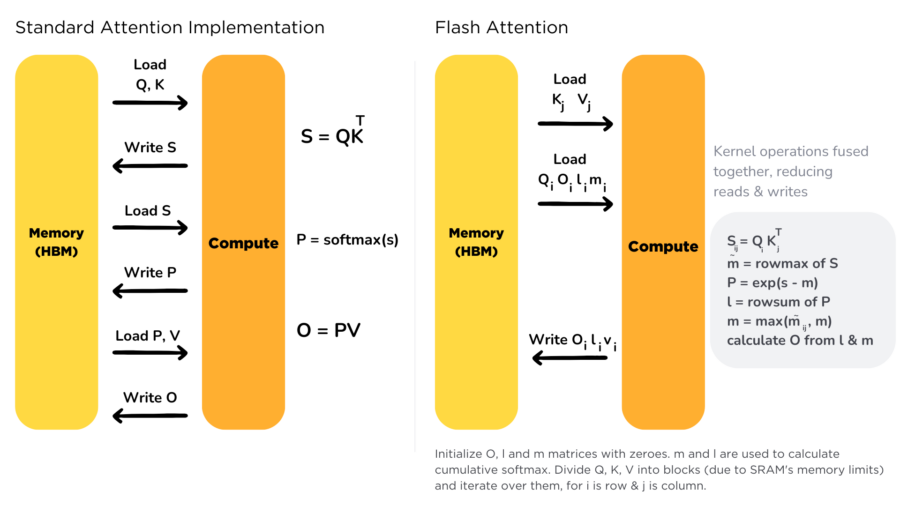
Im ersten Schritt werden die Q- und K-Matrizen in das HBM geladen, um S zu berechnen. Im zweiten Schritt wird S aus dem HBM gelesen, um Softmax darauf anzuwenden, das Ergebnis wird dann als P zurück in das HBM geschrieben. Dieser Schritt dauert am längsten.
Aus dem YouTube-Video von Aleksa Gordić mit FlashAttention-Autor Tri Dao: Das Diagramm erklärt, dass das Lesen und Schreiben der Zwischenmatrizen (S und A) der Hauptflaschenhals bei der Berechnung der Attention ist. Beachte, dass A in diesem Diagramm dasselbe ist wie P im obigen Algorithmus.
FlashAttention ist IO-bewusst
Da wir festgestellt haben, dass die Standard-Implementation der Attention aufgrund redundanter Lese- und Schreibvorgänge im langsamen GPU-Speicher (HBM) keine IO-Bewusstheit besitzt, werfen wir einen Blick auf die Hürden, die FlashAttention überwinden musste, um IO-Bewusstheit zu erreichen.
Kernel Fusion
FlashAttention steigert die Leistung, indem es die Berechnung der Attention in einen einzigen CUDA-Kernel fusioniert. Während Kernel Fusion einfach erscheinen mag, musste der FlashAttention-Algorithmus sorgfältig entworfen werden, um sicherzustellen, dass der On-Chip-Speicher nicht die Hardware-Grenzen überschreitet.
Tiling
Tiling ist eine Technik, bei der Daten in kleinere Blöcke oder „Tiles“ partitioniert werden, die in den On-Chip-Speicher passen. Durch tiling-unterstützte Kernel Fusion wird der Speicherbandbreitenbedarf reduziert, da die Daten aus dem globalen Speicher nur einmal pro Tile in die Streaming-Multiprozessoren übertragen werden.
Tiling ist besonders effektiv für assoziative Operationen wie die Matrixmultiplikation. Diese Eigenschaft erlaubt eine Neuanordnung der Berechnungen, ohne das Endergebnis zu verändern, was eine effiziente Verarbeitung kleinerer Tiles ermöglicht. Die Softmax-Operation in der Self-Attention ist jedoch nicht assoziativ, was bedeutet, dass die Reihenfolge der Berechnungen eine Rolle spielt.
Softmax assoziativ machen
Die Nutzung des „Online Softmax Trick“, um Softmax assoziativ zu machen, ist wohl die Schlüsselinnovation von FlashAttention.
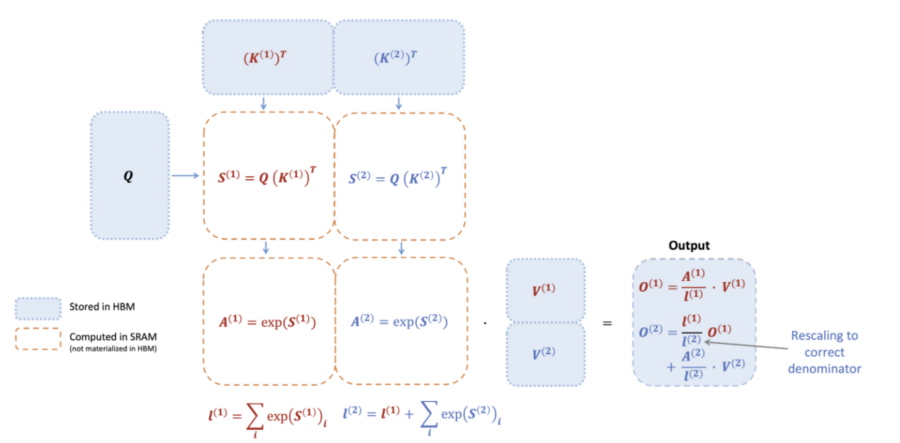
FlashAttention Vorwärtsdurchgang – Diagramm aus dem FlashAttention-2-Paper: Um die Softmax-Reduktion schrittweise durchzuführen, wird die Attention-Berechnung wie in der Abbildung umstrukturiert. Die Eingaben Q, K, V werden in Blöcke aufgeteilt. Anstatt die Zwischenmatrizen (S, A/P) im HBM zu speichern, werden sie im SRAM berechnet. Die Ausgabe wird vor der Addition am Ende auf den richtigen Nenner (Normalisierungsfaktor) reskaliert, sodass das gleiche Ergebnis wie bei der Standard-Implementation erreicht wird.
Recomputation im Backward-Pass
Redundante Lese- und Schreibvorgänge werden vermieden, indem die Zwischenmatrizen S und A/P nicht gespeichert, sondern im Backward-Pass neu berechnet werden. Dazu werden die Ausgabe O und die Softmax-Normalisierungsstatistiken (m, l) gespeichert, um die Zwischenmatrizen S und A/P im Backward-Pass aus den Q-, K-, V-Blöcken im SRAM erneut zu berechnen.
Fazit
Durch die geschickte Neuanordnung der Attention-Berechnung mit klassischen Techniken wie Tiling und Recomputation zur optimalen Nutzung der asymmetrischen GPU-Speicherhierarchie beschleunigte FlashAttention den Attention-Mechanismus und reduzierte den Speicherbedarf von quadratisch auf linear in Bezug auf die Sequenzlänge. Dieser Algorithmus zeigt eindrucksvoll sowohl die Kunst als auch die Effektivität von hardwarebewussten Algorithmen.
