
Random-Forest-Algorithmus im Machine Learning: Funktionsweise und Bedeutung
Zu den am häufigsten eingesetzten Algorithmen im Machine Learning zählt der Random Forest. Dieses Verfahren wird sowohl für Klassifikation als auch für Regression genutzt. Häufig erzielt es eine hohe Treffgenauigkeit, weshalb es besonders bei Klassifikationsaufgaben sehr beliebt ist. Ein Random Forest entsteht durch die Kombination vieler Entscheidungsbäume. In der Regel gilt: Je mehr Bäume enthalten sind, desto leistungsfähiger und ausgereifter wird das Modell. Jeder Baum liefert eine eigene Vorhersage, und das Endergebnis ergibt sich aus einer Mehrheitsentscheidung – ein Ansatz, der Stabilität und Widerstandsfähigkeit verbessert. In diesem Beitrag schauen wir uns an, was im Inneren eines Random Forest passiert, und setzen ihn anschließend in Python um, um die Arbeitsweise praktisch nachzuvollziehen.
Warum Random Forest?
Random Forest ist ein Algorithmus des überwachten Lernens, der besonders häufig für Klassifikationsaufgaben verwendet wird. Beim überwachten Lernen trainiert das Modell mit gelabelten Beispielen, wodurch der Lernprozess gezielt gesteuert wird. Eine zentrale Stärke von Random Forest ist seine Vielseitigkeit: Er eignet sich sowohl für Klassifikation als auch für Regression. Das Verfahren kombiniert die Ergebnisse mehrerer Entscheidungsbäume, um präzise Vorhersagen zu erzeugen. Obwohl viele Bäume zunächst nach Overfitting klingen könnten, tritt dieses Problem in der Praxis meist nicht auf. Stattdessen wird das Ergebnis gewählt, das am häufigsten von den einzelnen Bäumen vorhergesagt wird (Mehrheitsvotum). Dadurch entsteht eine robuste, zuverlässige und anpassungsfähige Leistung. In den folgenden Abschnitten betrachten wir, wie Random Forests aufgebaut sind und wie sie Schwächen einzelner Entscheidungsbäume verringern.
Nachteile von Entscheidungsbäumen
Ein Entscheidungsbaum ist ein Klassifikationsmodell, das ein festes Regelwerk erstellt, um Beziehungen zwischen Datenpunkten zu beschreiben. Beobachtungen (Datenpunkte) werden anhand eines Attributs so aufgeteilt, dass die entstehenden Gruppen möglichst deutlich voneinander abweichen, während die Elemente innerhalb einer Gruppe möglichst ähnlich sind. Anders ausgedrückt: Der Abstand zwischen den Klassen soll klein sein, und der Abstand innerhalb der Klassen soll groß sein. Das wird mithilfe verschiedener Methoden wie Information Gain, Gini Index und weiteren umgesetzt.
Es gibt mehrere Einschränkungen, die den reibungslosen Einsatz von Entscheidungsbäumen erschweren können, darunter:
- Overfitting-Gefahr bei sehr tiefen Bäumen: Entscheidungsbäume können überanpassen, wenn sie zu tief wachsen. Mit jeder weiteren Aufteilung werden mehr Attribute berücksichtigt. Der Baum versucht, das Trainingsset möglichst perfekt abzubilden, lernt dadurch zu viele Details der Trainingsdaten und verliert an Generalisierungsfähigkeit.
- Gieriges, lokal optimales Splitting: Entscheidungsbäume arbeiten gierig und neigen dazu, lokal optimale Entscheidungen zu finden, statt die global beste Lösung zu betrachten. In jedem Schritt wird eine Methode genutzt, um die beste Aufteilung zu bestimmen. Der lokal beste Knoten ist jedoch nicht zwingend der global beste. Genau hier hilft Random Forest, diese Probleme abzufedern.
Von Entscheidungsbäumen zu Random Forests
Das Problem mit einzelnen Entscheidungsbäumen
Entscheidungsbäume sind leicht anzuwenden, stoßen jedoch häufig auf Overfitting, hohe Varianz oder Bias – vor allem dann, wenn der Baum zu tief oder zu flach ist. Ein einzelner Baum kann zudem falsche Vorhersagen liefern, wenn er mit verrauschten oder verzerrten Daten trainiert wird.
Die Idee: Viele Bäume kombinieren
Um diese Probleme zu lösen, wurde vorgeschlagen, viele Bäume zu einem stärkeren Modell zusammenzuführen – einem Ensemble. Dieses Konzept wurde 1995 von Tin Kam Ho bei Bell Laboratories vorgestellt und bildete die Grundlage für den Random-Forest-Algorithmus.
Die Stärke des Waldes
Eine Gruppe von Bäumen (ein Wald) kann Fehler einzelner Bäume ausgleichen. Trifft ein Baum eine falsche Entscheidung, können andere Bäume richtig liegen. Durch die Kombination entsteht insgesamt eine genauere und stabilere Vorhersage. Für Klassifikation gilt: Jeder Baum gibt eine „Stimme“ für ein Klassenlabel ab. Das Label mit den meisten Stimmen wird als Endergebnis ausgegeben. Bei Regressionsaufgaben liefert jeder Baum eine numerische Vorhersage, und das finale Ergebnis ergibt sich als Durchschnitt aller Werte.
Zufälligkeit macht stärker
Während ein Entscheidungsbaum bei jeder Aufteilung stets die besten Merkmale auswählen möchte, wählt Random Forest Merkmale zufällig aus. Dadurch unterscheiden sich die Bäume stärker voneinander, was Overfitting entgegenwirkt.
Die Rolle von Bagging (Bootstrap Aggregating)
Random Forest basiert auf einer Technik namens Bagging (Bootstrap Aggregation). Dabei werden mehrere Datensätze erzeugt, indem zufällig aus dem Originaldatensatz gezogen wird – mit Zurücklegen. Jeder dieser Stichprobendatensätze trainiert einen eigenen Entscheidungsbaum. So wird die Varianz reduziert und die Gesamtgenauigkeit verbessert, indem die Vorhersagen aller Bäume zusammengeführt werden.
Feature Bagging – der Random-Forest-Kniff
Random Forest geht noch einen Schritt weiter und randomisiert nicht nur die Datenstichproben, sondern auch die verwendeten Features. Jeder Baum erhält eine eigene Feature-Teilmenge – das nennt man Feature Bagging. Dadurch sehen die Bäume nicht alle gleich aus, und die Vielfalt im Wald steigt.
Warum das so gut funktioniert
Die Kombination aus zufälligen Daten, zufälligen Features und vielen Bäumen erzeugt ein Modell, das weniger anfällig für Rauschen ist, seltener überanpasst und meist genauer ist als ein einzelner Entscheidungsbaum.
Unterschied zwischen Entscheidungsbäumen und Random Forests
| Merkmal | Entscheidungsbaum | Random Forest |
|---|---|---|
| Grundkonzept | Erstellt eine einzelne Baumstruktur, indem Entscheidungsregeln auf Basis der Eingabemerkmale aufgebaut werden. | Erstellt mehrere Entscheidungsbäume mithilfe zufälliger Teilmengen von Daten und Features im Rahmen eines Ensemble-Learning-Ansatzes. |
| Feature-Auswahl | Wählt für jeden Split das optimale Merkmal anhand von Metriken wie Gini-Impurity oder Entropie aus. | Nutzt bei jedem Split eine zufällige Teilmenge von Features, um die Vielfalt zwischen den Bäumen zu erhöhen. |
| Vorhersagemethode | Erzeugt Vorhersagen mithilfe eines einzelnen Entscheidungsbaums. | Kombiniert Vorhersagen vieler Bäume durch Mehrheitsabstimmung (Klassifikation) oder Mittelwertbildung (Regression). |
| Overfitting-Risiko | Anfälliger für Overfitting, insbesondere bei tiefen Bäumen oder kleinen Datensätzen. | Weniger anfällig für Overfitting durch Zufälligkeit und Ensemble-Mittelung. |
| Genauigkeit | Häufig geringere Genauigkeit aufgrund höherer Varianz und starker Abhängigkeit von den Trainingsdaten. | Erreicht meist eine höhere Genauigkeit durch aggregierte Vorhersagen aus mehreren Bäumen. |
| Interpretierbarkeit | Leicht verständlich und gut visualisierbar, mit transparenten Entscheidungsregeln. | Schwieriger zu interpretieren, da Vorhersagen aus vielen kombinierten Bäumen entstehen. |
| Rechenaufwand | Rechenleicht, da nur ein einzelner Baum trainiert wird. | Rechenintensiver, da mehrere Bäume trainiert und ausgewertet werden müssen. |
| Trainingszeit | Schnellere Trainingszeit, da weniger Berechnungen erforderlich sind. | Langsameres Training aufgrund der Erstellung vieler Bäume. |
| Umgang mit Rauschen und Varianz | Sensibel gegenüber verrauschten Daten und kleinen Änderungen im Datensatz, die die Baumstruktur stark beeinflussen können. | Besonders leistungsfähig bei großen Datensätzen mit vielen Features. |
| Eignung für Datensätze | Funktioniert gut bei kleinen bis mittelgroßen Datensätzen. | Funktioniert besser bei großen Datensätzen mit vielen Features. |
| Typische Anwendungsfälle | Geeignet für interpretierbare Modelle und einfache Entscheidungsunterstützungssysteme. | Häufig eingesetzt für hochgenaue Anwendungen wie Betrugserkennung, Risikoanalysen und medizinische Diagnostik. |
Anwendungen von Random Forests
Der Random-Forest-Classifier wird in vielen Bereichen wie Banking, Medizin und E-Commerce eingesetzt, da er eine starke Klassifikationsleistung bietet und dadurch über die Jahre zunehmend verbreitet wurde. Er wird verwendet, um Muster im Kundenverhalten zu erkennen, Remote-Sensing-Aufgaben zu unterstützen und Trends an Aktienmärkten zu analysieren. Im Gesundheitswesen hilft er beim Erkennen von Pathologien, indem häufige Muster identifiziert werden, und im Finanzbereich unterstützt er maßgeblich dabei, betrügerische von nicht betrügerischen Aktivitäten zu unterscheiden.
Random Forest von innen verstehen: Training, Vorhersage & Bewertung
Wie die meisten Machine-Learning-Algorithmen umfasst Random Forest zwei zentrale Phasen: Training und Testing. In der einen Phase wird der Wald aufgebaut, in der anderen werden Vorhersagen aus Testdaten erzeugt, die dem Modell übergeben werden. Zusätzlich betrachten wir die mathematische Logik, die das Pseudocode-Grundgerüst trägt.
Während des Trainings beginnt das Verfahren für jede Iteration b in 1, 2, … B (wobei B die Gesamtzahl der Entscheidungsbäume darstellt) damit, Bagging anzuwenden, um zufällige Daten-Teilmengen zu erzeugen. Aus einem Trainingsdatensatz X und Y werden n Trainingsbeispiele mit Zurücklegen gezogen, um Xb und Yb zu bilden. Aus den verfügbaren Features werden zufällig N Features ausgewählt, und aus dieser Teilmenge wird der beste Split-Knoten n berechnet. Mithilfe des gewählten Split-Punkts wird der Knoten entsprechend aufgeteilt. Dieser Ablauf – Features auswählen, besten Split finden und Knoten teilen – wird wiederholt, bis l Knoten entstanden sind. Das gesamte Verfahren läuft weiter, bis B Bäume gebaut wurden. In der Testphase werden Vorhersagen für unbekannte Samples x’ erzeugt, indem die Ausgaben aller einzelnen Regressionsbäume aggregiert (gemittelt) werden.
Im Fall der Klassifikation werden die Stimmen aller Bäume gesammelt, und die Klasse mit den meisten Stimmen wird als finale Vorhersage verwendet.
Die optimale Anzahl an Bäumen in einem Random Forest (B) lässt sich anhand der Datensatzgröße, Cross-Validation oder Out-of-Bag-Error bestimmen. Schauen wir uns diese Begriffe an.
Cross-Validation wird häufig genutzt, um Overfitting in Machine-Learning-Modellen zu reduzieren. Dabei wird mit Trainingsdaten trainiert und über mehrere Durchläufe auf unterschiedlichen Test-Splits geprüft. Diese Durchläufe werden durch k beschrieben, daher der Begriff k-fold cross-validation. Das kann helfen, die Anzahl an Bäumen anhand des k-Werts abzuleiten. Out-of-bag error ist der durchschnittliche Vorhersagefehler für jedes Trainingssample xi, berechnet nur mit den Bäumen, die xi nicht in ihrer Bootstrap-Stichprobe enthalten. Das ähnelt einer Leave-one-out-Cross-Validation.
Feature-Wichtigkeit berechnen (Feature Engineering)
Als Nächstes sehen wir uns an, wie Random Forest in Python mit der scikit-learn-Bibliothek umgesetzt werden kann. Ein sinnvoller erster Schritt ist die Bewertung der Feature-Wichtigkeit, weil sie verdeutlicht, welche Merkmale Vorhersagen am stärksten beeinflussen. Scikit-learn bietet dafür einen Feature-Importance-Indikator, der die relative Bedeutung aller Features abbildet. Dieser Wert wird über den Gini Index oder den Mean decrease in impurity (MDI) berechnet und beschreibt, wie stark die Unreinheit durch Splits mit diesem Feature über alle Bäume hinweg reduziert wird.
Der Score zeigt den Beitrag jedes Features während des Trainings und normalisiert die Werte so, dass ihre Summe 1 ergibt. Dadurch lassen sich wichtige Features leichter auswählen und solche entfernen, die keinen oder nur geringen Einfluss auf den Modellaufbau haben. Weniger Features zu verwenden ist sinnvoll, weil es Overfitting reduziert – ein Effekt, der häufig auftritt, wenn sehr viele Attribute vorhanden sind.
Random Forest für Regression: Kontinuierliche Werte vorhersagen
Obwohl Random Forest oft mit Klassifikation verknüpft wird, eignet er sich ebenso hervorragend für Regressionsaufgaben, bei denen ein kontinuierlicher numerischer Wert geschätzt werden soll (zum Beispiel Hauspreise, Temperaturwerte oder Umsätze).
So funktioniert es
Statt – wie bei der Klassifikation – per Abstimmung ein Klassenlabel zu bestimmen, gibt jeder Entscheidungsbaum im Wald eine numerische Schätzung aus. Das Modell bildet daraus das Endergebnis, indem es die Vorhersagen aller Bäume mittelt. Diese Mittelung senkt die Varianz und führt meist zu Vorhersagen, die sowohl genauer als auch stabiler sind.
Schritt-für-Schritt-Logik
- Mehrere Entscheidungsbäume werden auf zufälligen Teilmengen des Datensatzes trainiert (einschließlich Zeilen und Spalten).
- Jeder Baum liefert für den gegebenen Eingabepunkt eine numerische Vorhersage.
- Das Modell mittelt alle Vorhersagen der Bäume und erzeugt daraus das finale Ergebnis.
Wenn ein Random Forest B Bäume enthält und jeder Baum eine Vorhersage hb(x) liefert, ergibt sich die finale Prognose ŷ für eine Eingabe x wie folgt:
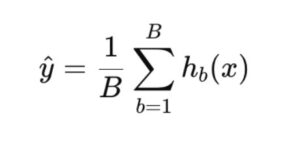
Wobei:
- hb(x) = Vorhersage des b-ten Baums
- B = Gesamtzahl der Bäume im Wald
- ŷ = finaler vorhergesagter Wert (Durchschnitt aller Bäume)
RF kann nichtlineare Zusammenhänge gut abbilden und reduziert Overfitting durch Mittelung. Außerdem sind Random-Forest-Modelle für Regression häufig robust gegenüber Ausreißern und kommen mit fehlenden Daten gut zurecht.
Random-Forest-Hyperparameter in Scikit-learn
Scikit-learns RandomForestClassifier bietet mehrere einstellbare Hyperparameter, mit denen sich Komplexität, Geschwindigkeit und Genauigkeit beeinflussen lassen. Im Folgenden die wichtigsten:
1. n_estimators – Anzahl der Bäume im Wald
Dieser Parameter legt fest, wie viele Entscheidungsbäume gebaut und im Random Forest zusammengeführt werden. In vielen Fällen steigt Genauigkeit und Stabilität mit einer höheren Baumanzahl, weil mehr Vorhersagen gemittelt werden und dadurch die Varianz sinkt. Gleichzeitig steigen jedoch Rechenzeit und Speicherbedarf. In scikit-learn lag der Default in Version 0.20 bei 10, wurde aber ab Version 0.22 auf 100 erhöht, was einen praxisnahen Kompromiss zwischen Modellleistung und Trainingseffizienz darstellt.
2. criterion – Funktion zur Split-Bewertung
Dieses Setting bestimmt, nach welchem Kriterium die Qualität eines Splits an einem Knoten bewertet wird. Am häufigsten werden ‚gini‘ und ‚entropy‘ verwendet. Der ‚gini‘-Index misst die Unreinheit über die Wahrscheinlichkeit, dass ein zufällig gewähltes Element falsch klassifiziert würde, wenn es anhand der Klassenverteilung im Knoten zufällig gelabelt wird. ‚entropy‘ basiert dagegen auf Information Gain und beschreibt, wie stark die Unsicherheit nach dem Split sinkt. Während ‚gini‘ standardmäßig gesetzt ist und meist schneller berechnet wird, kann ‚entropy‘ je nach Datensatz gelegentlich etwas bessere Ergebnisse liefern.
3. max_depth – Maximale Baumtiefe
max_depth begrenzt, wie tief ein Baum im Random Forest wachsen darf. Ist der Wert auf None gesetzt, wird so lange gesplittet, bis alle Blätter rein sind, also keine weitere Verbesserung möglich ist. Tiefe Bäume können komplexe Muster erfassen, erhöhen aber das Overfitting-Risiko. Eine feste maximale Tiefe hilft, Overfitting zu begrenzen und kann außerdem die Rechenzeit senken, wodurch ein effizienteres und besser generalisierendes Modell entsteht.
4. max_features – Features pro Split
Dieser Parameter steuert, wie viele Features beim Suchen nach dem besten Split an einem Knoten betrachtet werden. Für Klassifikation ist der Standard meist ‚auto‘ oder ’sqrt‘, was der Quadratwurzel der Gesamtanzahl an Features entspricht. Eine weitere Option ist ‚log2‘, basierend auf dem Logarithmus zur Basis 2. Alternativ kann eine ganze Zahl angegeben werden, um eine exakte Feature-Anzahl zu setzen, oder ein Float (z. B. 0.5), um einen Anteil aller Features zu definieren. Das Tuning dieses Parameters hilft, Vorhersagequalität und Rechenaufwand auszubalancieren. Die Randomisierung der Features pro Split steigert die Vielfalt der Bäume, reduziert Korrelation und wirkt Overfitting entgegen.
5. min_samples_leaf – Mindestanzahl Samples pro Blatt
min_samples_leaf definiert, wie viele Samples mindestens in einem Blattknoten (Endknoten) enthalten sein müssen. Höhere Werte führen zu konservativeren Bäumen, weil Splits vermieden werden, die extrem kleine Blätter erzeugen. Dadurch sinkt die Overfitting-Gefahr, und die Generalisierung verbessert sich oft – besonders bei verrauschten oder unausgeglichenen Datensätzen. Standardmäßig ist der Wert 1, was maximale Flexibilität erlaubt, aber auch das Overfitting-Risiko erhöhen kann.
6. n_jobs – Anzahl paralleler Jobs
Dieser Parameter legt fest, wie viele CPU-Kerne parallel für das Training genutzt werden dürfen. Mit None oder 1 läuft das Training auf einem Kern. n_jobs=-1 sorgt dafür, dass alle verfügbaren Kerne genutzt werden, was Training und Vorhersagen deutlich beschleunigen kann – insbesondere bei großen Datensätzen oder vielen Bäumen.
7. oob_score – Out-of-Bag-Bewertung
Dieser Boolean bestimmt, ob Out-of-bag-(OOB)-Samples zur Bewertung der Modellleistung genutzt werden sollen. OOB-Samples sind Datenpunkte, die nicht in der Bootstrap-Stichprobe eines bestimmten Baums enthalten waren. Wenn oob_score True ist, nutzt das Modell diese ausgeschlossenen Daten wie ein integriertes Validierungsset, um den Generalisierungsfehler zu schätzen. Das spart Zeit, weil separate Cross-Validation entfallen kann, und ist besonders bei großen Datensätzen nützlich. Standardmäßig steht dieser Parameter auf False.
Den Algorithmus programmieren
Schritt 1: Daten erkunden
Importiere zunächst die MNIST-Daten aus der datasets-Bibliothek im sklearn-Paket.
from sklearn import datasets
mnist = datasets.load_digits()
X = mnist.data
Y = mnist.target
Als Nächstes untersuchst du die Daten, indem du sowohl die Eingabewerte (data) als auch die Ausgabelabel (target) ausgibst.
[[ 0. 0. 5. 13. 9. 1. 0. 0. 0. 0. 13. 15. 10. 15. 5. 0. 0. 3.
15. 2. 0. 11. 8. 0. 0. 4. 12. 0. 0. 8. 8. 0. 0. 5. 8. 0.
0. 9. 8. 0. 0. 4. 11. 0. 1. 12. 7. 0. 0. 2. 14. 5. 10. 12.
0. 0. 0. 0. 6. 13. 10. 0. 0. 0.]]
[0]
print(mnist.data.shape) print(mnist.target.shape) Output: (1797, 64) (1797,)
Schritt 2: Daten vorverarbeiten
In diesem Schritt wird mit Pandas ein DataFrame erstellt. Die Zielwerte liegen in y und die Eingabedaten in X. pd.Series wird genutzt, um ein 1D-Array mit int-Datentyp zu erzeugen, das auf Kategorienwerte begrenzt ist. pd.DataFrame wandelt die Eingabedaten in eine tabellarische Form um. head() liefert die ersten fünf Zeilen des DataFrames. Gib sie wie folgt aus.
import pandas as pd
y = pd.Series(mnist.target).astype('int').astype('category')
X = pd.DataFrame(mnist.data)
print(X.head())
print(y.head())
Output:
0 1 2 3 4 5 6 7 8 9 ... 54 55 56 \
0 0.0 0.0 5.0 13.0 9.0 1.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0
1 0.0 0.0 0.0 12.0 13.0 5.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0
2 0.0 0.0 0.0 4.0 15.0 12.0 0.0 0.0 0.0 0.0 ... 5.0 0.0 0.0
3 0.0 0.0 7.0 15.0 13.0 1.0 0.0 0.0 0.0 8.0 ... 9.0 0.0 0.0
4 0.0 0.0 0.0 1.0 11.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0
57 58 59 60 61 62 63
0 0.0 6.0 13.0 10.0 0.0 0.0 0.0
1 0.0 0.0 11.0 16.0 10.0 0.0 0.0
2 0.0 0.0 3.0 11.0 16.0 9.0 0.0
3 0.0 7.0 13.0 13.0 9.0 0.0 0.0
4 0.0 0.0 2.0 16.0 4.0 0.0 0.0
[5 rows x 64 columns]
0 0
1 1
2 2
3 3
4 4
dtype: category
Categories (10, int64): [0, 1, 2, 3, ..., 6, 7, 8, 9]
Teile die Eingabe (X) und Ausgabe (y) in Trainings- und Testdaten auf, indem du train_test_split aus sklearn.model_selection verwendest. test_size gibt an, dass 70% der Datenpunkte im Training und 30% im Testing liegen.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
X_train ist die Eingabe in den Trainingsdaten.
X_test ist die Eingabe in den Testdaten.
y_train ist die Ausgabe in den Trainingsdaten.y_test ist die Ausgabe in den Testdaten.
Schritt 3: Classifier erstellen
Trainiere das Modell mit den Trainingsdaten, indem du RandomForestClassifier aus sklearn.ensemble nutzt. Der Parameter n_estimators bedeutet, dass 100 Bäume im Random Forest enthalten sind. Die Methode fit() trainiert das Modell mit X_train und y_train.
from sklearn.ensemble import RandomForestClassifier
clf=RandomForestClassifier(n_estimators=100)
clf.fit(X_train,y_train)
Erzeuge Vorhersagen, indem du predict() auf X_test anwendest. Die prognostizierten Werte werden in y_pred gespeichert.
y_pred=clf.predict(X_test)
Prüfe die Genauigkeit mit accuracy_score aus sklearn.metrics. Die Accuracy wird anhand der tatsächlichen Werte (y_test) und der vorhergesagten Werte (y_pred) berechnet.
from sklearn.metrics import accuracy_score
print("Accuracy: ", accuracy_score(y_test, y_pred))
Output: Accuracy: 0.9796296296296
Das entspricht einer geschätzten Genauigkeit von 97,96% für den trainierten Random-Forest-Classifier – ein sehr gutes Ergebnis.
Schritt 4: Feature-Wichtigkeit schätzen
In den vorherigen Abschnitten wurde Feature Importance als wichtiges Merkmal des Random-Forest-Classifiers genannt. Jetzt berechnen wir das.
feature_importances_ ist in sklearn als Teil von RandomForestClassifier verfügbar. Extrahiere die Werte und sortiere sie absteigend, damit die wichtigsten zuerst erscheinen.
feature_imp=pd.Series(clf.feature_importances_).sort_values(ascending=False)
print(feature_imp[:10])
Output: 21 0.049284 43 0.044338 26 0.042334 36 0.038272 33 0.034299 dtype: float64
Die linke Spalte steht für das Attribut-Label (zum Beispiel das 26. Attribut, das 43. Attribut usw.), und die rechte Spalte zeigt den Wert der Feature-Wichtigkeit.
Schritt 5: Feature-Wichtigkeit visualisieren
Importiere matplotlib, pyplot und seaborn, um die Feature-Importance-Ergebnisse zu visualisieren. Gib die Input- und Output-Werte so an, dass x durch die Feature-Importance-Werte definiert ist und y die 10 wichtigsten Features aus den 64 Attributen darstellt.
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
sns.barplot(x=feature_imp, y=feature_imp[:10].index)
plt.xlabel('Feature Importance Score')
plt.ylabel('Features')
plt.title("Visualizing Important Features")
plt.legend()
plt.show()
Vorteile von Random Forest
- Random Forest ist ein äußerst vielseitiger und zuverlässiger Algorithmus, der bei einer breiten Palette von Machine-Learning-Problemen sehr gute Ergebnisse liefert.
- Fehlende Werte können effektiv verarbeitet werden, wodurch häufig keine explizite Datenimputation erforderlich ist.
- Neben überwachten Lernverfahren kann Random Forest auch für unüberwachte Aufgaben wie Clustering angepasst werden, indem proximitätsbasierte Ähnlichkeitsmaße genutzt werden.
- Der Algorithmus ist vergleichsweise leicht zu verstehen und zu implementieren, insbesondere mit Machine-Learning-Bibliotheken wie scikit-learn.
- Selbst mit minimalem Hyperparameter-Tuning erzielt Random Forest häufig bereits sehr starke Baseline-Ergebnisse.
- Durch die Aggregation von Vorhersagen aus mehreren unabhängigen Entscheidungsbäumen wird das Risiko von Overfitting deutlich reduziert.
- Random Forest unterstützt außerdem die Analyse der Feature-Wichtigkeit und eignet sich daher gut zur Identifikation der einflussreichsten Variablen in einem Datensatz.
- Besonders bei hochdimensionalen Datensätzen mit vielen Eingabemerkmalen zeigt Random Forest eine sehr starke Performance.
Nachteile von Random Forest
- Training und Inferenz mit Random Forest können rechenintensiv werden, insbesondere bei großen Datensätzen oder einer hohen Anzahl an Bäumen.
- Das Modell ist weniger interpretierbar als ein einzelner Entscheidungsbaum, da die Entscheidungslogik auf zahlreiche Bäume innerhalb des Ensembles verteilt ist.
- Eine größere Anzahl an Bäumen verbessert häufig die Genauigkeit, kann jedoch die Trainingszeit erheblich verlängern.
- Auch die Vorhersagelatenz kann ansteigen, was in Anwendungen mit schnellen oder Echtzeit-Antwortanforderungen problematisch sein kann.
Zusammenfassung und Fazit
Random Forest ist ein leistungsstarker, einsteigerfreundlicher Machine-Learning-Algorithmus, der Einfachheit und Performance gut ausbalanciert. Indem er die Stärken vieler Entscheidungsbäume kombiniert, begrenzt er Overfitting und liefert starke Ergebnisse für Klassifikation und Regression. Ob du mit strukturierten Datensätzen arbeitest oder reale Business-Probleme löst: Random Forest ist ein zuverlässiges Werkzeug im ML-Toolkit.
