
Byte Latent Transformers (BLT): Ein tokenizerfreier Ansatz für Sprachmodelle
Große Sprachmodelle (LLMs) basieren traditionell auf Tokenisierung, um lange Sätze oder Ausdrücke zu verarbeiten, indem sie in kleinere Tokens zerlegt werden, die anschließend von Machine-Learning-Modellen verarbeitet werden. Dieses Verfahren bringt jedoch Probleme mit sich, etwa Verzerrungen bei der Token-Komprimierung, eine erhöhte Anfälligkeit für Störungen und Schwierigkeiten bei mehrsprachigen Inhalten. Doch was wäre, wenn sich Tokenisierung vollständig vermeiden ließe und Modelle direkt auf Rohbytes trainiert werden könnten, ohne dabei Effizienz oder Leistung einzubüßen?
In diesem Beitrag geht es um Byte Latent Transformers, eine tokenizerfreie beziehungsweise bytebasierte LLM-Architektur mit der Bezeichnung BLT.
Statt sich auf ein fest definiertes Token-Vokabular zu stützen, fassen Byte Latent Transformers Bytes dynamisch zu latenten Patches zusammen. Dadurch kann das Modell Rechenleistung gezielt dort einsetzen, wo sie wirklich gebraucht wird, was sowohl die Effizienz als auch die Robustheit verbessert. Im Vergleich zu früheren Verfahren kommen BLT-Modelle besser mit verrauschten Eingaben zurecht, erfassen zeichenbasierte Strukturen präziser und verarbeiten unterschiedliche Sprachen deutlich effizienter.
Voraussetzungen
Ein grundlegendes Verständnis der nachfolgenden Konzepte erleichtert das Verständnis von Byte Latent Transformers.
Tokenisierung in Sprachmodellen
- Herkömmliche LLMs wie GPT oder Llama verwenden Subword-Tokenisierungsmethoden wie Byte Pair Encoding (BPE) oder WordPiece, um Text vor dem Training in Tokens aufzuteilen.
- Diese Tokens sind vordefinierte Wort- oder Zeichenfragmente, die das Modell während des Trainings erlernt.
Grundlagen der Transformer-Architektur
Der Transformer bildet das Fundament der meisten modernen LLMs. Zu seinen zentralen Bestandteilen gehören:
- Self-Attention (wie Modelle verschiedene Teile der Eingabedaten gewichten).
- Feed-Forward-Schichten (werden genutzt, um Muster in Daten zu erlernen).
Entropie in Sprachmodellen
- Entropie beschreibt die Unsicherheit von Vorhersagen. Eine hohe Entropie bedeutet, dass das Modell beim nächsten Byte oder Token unsicher ist, während eine niedrige Entropie auf eine hohe Vorhersagesicherheit hinweist.
- Bei BLT wird Entropie verwendet, um Patch-Grenzen dynamisch festzulegen.
Was sind Byte Latent Transformers?
Byte Latent Transformers (BLTs) machen eine vordefinierte Tokenisierung überflüssig. Klassische KI-Systeme, darunter auch Modelle wie Llama 2 und Llama 3, sind auf Tokenizer angewiesen, die Texte vor der Modellverarbeitung in kleinere Einheiten zerlegen. Auch wenn dieses Verfahren gut funktioniert, stößt es insbesondere bei vielen Sprachen oder unbekannten Datentypen an Grenzen.
BLTs arbeiten stattdessen direkt mit Rohbytes und organisieren diese nicht in festen Tokens, sondern in sogenannten „Patches“. Dieses patchbasierte Prinzip macht das Modell flexibler und effizienter und senkt zugleich die Rechenkosten bei der Textverarbeitung. Da größere Patches die Anzahl der notwendigen Verarbeitungsschritte verringern, lassen sich BLTs besser skalieren, ohne dass das Trainingsbudget drastisch steigt. Dadurch sind sie besonders interessant für große Datensätze und sprachlich komplexe Eingaben, während gleichzeitig die Inferenzgeschwindigkeit verbessert wird.
Auch wenn BLTs noch weiter optimiert werden, deuten erste Ergebnisse darauf hin, dass sie mit klassischen Modellen im großen Maßstab mithalten oder sie sogar übertreffen können. Mit fortschreitender Forschung könnten BLTs den Weg für effizientere und universeller einsetzbare KI-Modelle ebnen.
Was ist Entropy Patching?
Zunächst ist es hilfreich zu verstehen, was Entropie im Zusammenhang mit BLT bedeutet. In diesem Fall steht Entropie für den Grad der Unsicherheit innerhalb der verarbeiteten Byte-Sequenzen. Vereinfacht gesagt zeigt sie, wie unsicher das Modell bei der Vorhersage des nächsten Bytes in einer Sequenz ist.
- Ist die Entropie hoch, ist das Modell unsicherer darüber, welches Byte als Nächstes folgt.
- Ist die Entropie niedrig, ist das Modell bei der Vorhersage des nächsten Bytes deutlich sicherer.
- Entropie beschreibt, wie viel Zufälligkeit oder Unvorhersehbarkeit in einer Byte-Sequenz enthalten ist. In BLT beeinflusst die Entropie einer Byte-Sequenz folgende Bereiche:
- Kompressionseffizienz: Eine höhere Entropie bedeutet mehr einzigartige Muster, wodurch sich Daten schwieriger komprimieren lassen. Eine niedrigere Entropie weist auf besser vorhersehbare Strukturen hin, die sich effizienter darstellen lassen.
- Steuerung der Modellkomplexität: BLTs passen den Rechenaufwand anhand der Entropie an und bestimmen dadurch, wann der Latent Global Transformer eingesetzt werden soll, um unnötige Verarbeitung zu vermeiden.
- Repräsentationslernen: Durch das Erkennen von Mustern in Byte-Sequenzen lernen BLTs effiziente Repräsentationen, die Komplexität und Ausdrucksstärke in Einklang bringen.
Entropy Patching ist ein Verfahren, mit dem festgelegt wird, an welchen Stellen Byte-Sequenzen anhand der Unsicherheit der Vorhersage des nächsten Bytes in Patches aufgeteilt werden. Dadurch lassen sich Patch-Grenzen dynamisch bestimmen. Im Gegensatz zu starren regelbasierten Methoden, etwa einer Trennung anhand von Leerzeichen, verfolgt Entropy Patching einen datengestützten Ansatz und nutzt Entropieschätzungen, um Positionen zu identifizieren, an denen die Vorhersage des nächsten Bytes unsicher oder komplex wird.
Wie wird Entropie für Patch-Grenzen genutzt?
BLTs verwenden ein kleines bytebasiertes Sprachmodell (LM), um die Entropie jedes Bytes in einer Sequenz zu schätzen. Diese Berechnung erfolgt für jedes einzelne Byte (xi) und hilft dabei zu entscheiden, an welchen Stellen die Sequenz in Patches aufgeteilt werden soll.
Gleichung für die Entropie (H(xi))
Die Entropie (H(xi)) für jedes Byte (xi) wird wie folgt berechnet:
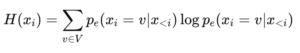
Durch diese Berechnung kann das Modell Patch-Grenzen adaptiv an den Stellen setzen, an denen die Daten unsicher oder komplex werden. Indem BLTs neue Grenzen in Bereichen mit hoher Entropie setzen, vermeiden sie unnötigen Rechenaufwand für gut vorhersagbare Abschnitte der Daten. Je unsicherer die Vorhersage des nächsten Bytes ist, desto wahrscheinlicher wird eine neue Patch-Grenze erzeugt.
Subword-Tokenisierung in LLMs
Moderne große Sprachmodelle, darunter auch Llama 3, arbeiten mit Subword-Tokenisierung. Dabei wird Text in kleinere Einheiten zerlegt, die jedoch nicht immer vollständige Wörter sind. Stattdessen kann es sich um Wortbestandteile, Silben oder noch kleinere Fragmente handeln. Der Tokenizer greift dabei auf ein vordefiniertes Inventar an Einheiten zurück, das aus den Trainingsdaten gelernt wurde. Diese Einheiten sind fest definiert und verändern sich nicht dynamisch.
Patches vs. Tokens
Im Unterschied zu Tokens sind Patches Byte-Sequenzen, die während der Modellverarbeitung dynamisch gebildet werden. Das bedeutet, dass sie nicht an ein festes Vokabular gebunden sind und je nach Eingabe unterschiedlich ausfallen können. In tokenbasierten Systemen hat das Modell keinen direkten Zugriff auf die zugrunde liegenden Rohbytes. Bei Patches hingegen verarbeitet das Modell die Rohbytes unmittelbar und gruppiert sie dynamisch.
Der Vorteil von BLT gegenüber Tokenisierung
In klassischen tokenbasierten Modellen führt eine Vergrößerung des Vokabulars in der Regel dazu, dass auch die Tokens größer werden. Dadurch sinkt zwar die Anzahl der Verarbeitungsschritte, gleichzeitig steigt jedoch der Rechenaufwand. BLT verändert dieses Verhältnis, indem es mehr Flexibilität bei der Gruppierung und Verarbeitung der Daten ermöglicht, was in bestimmten Fällen zu einer höheren Effizienz führt.
Wie entscheidet BLT, wann Daten aufgeteilt werden?
Während BLTs Text generieren, müssen sie in Echtzeit entscheiden, ob die aktuellen Daten den Beginn eines neuen Patches markieren sollen. Diese Entscheidung wird inkrementell getroffen, also ausschließlich auf Basis der bereits verarbeiteten Informationen, ohne Zugriff auf zukünftige Bytes. Genau das ist wichtig, weil BLT dynamisch arbeitet und nicht vorausblicken kann, um die Aufteilung zu bestimmen. Die Entscheidung erfolgt schrittweise, was als inkrementelles Patching bezeichnet wird.
Warum funktioniert Tokenisierung nicht auf dieselbe Weise?
Herkömmliche Tokenisierung arbeitet nicht in derselben inkrementellen Form. Wenn ein Tokenizer beispielsweise den Anfang eines Wortes verarbeitet, kann die endgültige Token-Aufteilung davon abhängen, welche Zeichen später im Wort folgen. Anders gesagt: Tokenisierung kann sich an zukünftigem Kontext orientieren. Das passt nicht zu einem Ansatz wie BLT, bei dem jede Entscheidung ohne Wissen über den weiteren Verlauf getroffen werden muss.
Architektur und Mechanismen: Einfach erklärt
Byte Latent Transformers bestehen aus drei Hauptkomponenten:
- Globales Transformer-Modell (Latent Global Transformer)
- Lokaler Encoder (wandelt Bytes in Patches um)
- Lokaler Decoder (wandelt Patches zurück in Bytes)
Jede dieser Komponenten übernimmt eine wesentliche Aufgabe, damit BLT effizient und skalierbar für die Sprachverarbeitung eingesetzt werden kann.
1. Globales Transformer-Modell (Latent Global Transformer)
- Dies ist die zentrale Verarbeitungseinheit von BLT. Sie verarbeitet Sequenzen von Patch-Repräsentationen anstelle einzelner Bytes.
- Das Modell arbeitet autoregressiv, das heißt, es sagt den nächsten Patch auf Grundlage der vorherigen Patches voraus.
- Es verwendet eine block-kausale Attention-Maske, sodass das Modell nur auf den aktuellen und die vorherigen Patches zugreift, was die Effizienz verbessert.
- Da dieser Bestandteil die höchsten Rechenkosten verursacht, entscheidet BLT gezielt, wann er eingesetzt wird, und optimiert so den Aufwand abhängig von der Komplexität der Eingabe.
2. Lokaler Encoder (Umwandlung von Bytes in Patches)
- Hierbei handelt es sich um einen kleineren und leichteren Transformer, der Rohbytes in Patch-Repräsentationen umwandelt.
- Er nutzt einen speziellen Cross-Attention-Mechanismus, um Byte-Informationen effizient in Patches zusammenzuführen.
- Außerdem enthält er hashbasierte n-Gramm-Embeddings, wodurch Muster aus mehreren aufeinanderfolgenden Bytes (von 3 bis 8 Bytes) erfasst werden können, um die Qualität der Repräsentation zu verbessern.
- Zusätzlich verwendet er innerhalb lokaler Bereiche eine block-kausale Attention-Maske, sodass sich jedes Byte beim Bilden von Patches nur auf nahegelegene Bytes bezieht.
3. Lokaler Decoder (Umwandlung von Patches zurück in Bytes)
- Dies ist ebenfalls ein kompakter Transformer, der jedoch die umgekehrte Aufgabe des Encoders übernimmt.
- Er erhält verarbeitete Patch-Repräsentationen und rekonstruiert daraus die ursprünglichen Byte-Sequenzen.
- Über Cross-Attention steuern die Patch-Repräsentationen die Generierung auf Byte-Ebene.
- Dadurch wird eine hohe Ausgabegenauigkeit sichergestellt, indem Byte-Details innerhalb jedes Patches weiter verfeinert werden.
Wie BLT als Gesamtsystem funktioniert
Encoding-Phase
- Der lokale Encoder fasst Bytes zu Patches zusammen, indem er Muster erkennt und Informationen effizient komprimiert.
- Hashbasierte n-Gramm-Embeddings helfen dabei, einen größeren Kontext zu erfassen, ohne den Rechenaufwand zu erhöhen.
Processing-Phase
- Der globale Transformer arbeitet mit Patch-Repräsentationen statt mit Rohbytes, was die Berechnung effizienter macht.
- Er nutzt adaptive Patch-Größen, sodass bei komplexem Text mehr Rechenleistung eingesetzt wird und bei gut vorhersagbaren Inhalten weniger.
Decoding-Phase
- Der lokale Decoder rekonstruiert die ursprüngliche Byte-Sequenz aus den verarbeiteten Patches mithilfe von Cross-Attention.
Herausforderungen
Auch wenn BLTs gegenüber traditionellen Transformern mehrere Vorteile bieten, bringen sie ebenfalls einige Einschränkungen mit sich:
- BLTs stützen sich derzeit auf Skalierungsgesetze, die ursprünglich für BPE-basierte Transformer entwickelt wurden und für diese Architektur möglicherweise nicht optimal sind. Zukünftige Forschung ist notwendig, um BLT-spezifische Skalierungsgesetze zu entwickeln, die Effizienz und Leistung weiter verbessern könnten.
- Bestehende Deep-Learning-Bibliotheken sind stark auf tokenizerbasierte Modelle optimiert, was es schwierig macht, mit BLTs dieselbe Effizienz zu erreichen.
- BLTs benötigen spezialisierte Implementierungen wie FlexAttention, können aber dennoch bei der tatsächlichen Laufzeit hinter BPE-basierten Modellen zurückbleiben.
- Erste Experimente zeigen, dass sich tokenizerbasierte Modelle wie Llama 3 in bytebasierte Systeme überführen lassen, doch dieser Prozess ist noch nicht vollständig optimiert.
- Weitere Forschung ist erforderlich, damit BLTs tokenizerbasierte Modelle ohne vollständiges Retraining erreichen oder übertreffen können.
FAQ zu Byte Latent Transformers (BLTs)
1. Worin unterscheidet sich BLT von traditionellen Transformern?
Traditionelle Transformer basieren auf Tokenisierung, bei der Text vor der Verarbeitung in kleinere Einheiten wie Wörter oder Subwords zerlegt wird. BLTs arbeiten stattdessen direkt mit Byte-Sequenzen und organisieren diese in Patches. Dadurch entfällt die Tokenisierung, und BLTs können effizient mit beliebigen Sprachen oder Datensätzen arbeiten, ohne auf vordefinierte Vokabulare angewiesen zu sein.
2. Welche Vorteile bietet BLT gegenüber Tokenisierung?
- Höhere Flexibilität: BLT funktioniert mit jeder Sprache und jedem Textformat, ohne einen Tokenizer zu benötigen.
- Verbesserte Effizienz: Größere Byte-Patches senken den Rechenaufwand und verbessern die Skalierbarkeit.
- Bessere Leistung im großen Maßstab: BLTs können mit tokenbasierten Modellen mithalten oder sie bei zunehmender Modellgröße übertreffen.
- Weniger Vorverarbeitung: Es ist nicht notwendig, separate Tokenizer für verschiedene Sprachen zu trainieren und feinzujustieren.
3. Ist BLT für mehrsprachige Daten geeignet?
Ja. Da BLTs mit Rohbytes statt mit sprachspezifischen Tokens arbeiten, können sie viele Sprachen ganz natürlich verarbeiten, auch solche mit komplexen Schriftsystemen. Dadurch eignen sie sich besonders gut für mehrsprachige KI-Modelle, weil keine separaten Tokenisierungsregeln pro Sprache erforderlich sind.
4. Lässt sich BLT in bestehende KI-Modelle integrieren?
Ja, BLTs lassen sich in bestehende KI-Architekturen integrieren, und erste Experimente zeigen vielversprechende Ergebnisse bei der Umwandlung tokenizerbasierter Systeme wie Llama 3 in bytebasierte Modelle. Auch wenn noch weitere Optimierungen notwendig sind, könnten BLTs künftig ohne vollständiges Neutraining in bestehende KI-Workflows eingebunden werden.
Fazit
Der Byte Latent Transformer (BLT) stellt einen wichtigen Wandel darin dar, wie Modelle Rohdaten auf Byte-Ebene verarbeiten können. Indem feste Tokens durch dynamische, entropiegesteuerte Patches ersetzt werden, bietet BLT einen flexibleren und effizienteren Weg, mit unterschiedlichen Datentypen und variierenden Rechenanforderungen umzugehen. Dieser Ansatz ermöglicht ein feineres Verständnis der Daten, eine bessere Recheneffizienz und eine höhere Anpassungsfähigkeit an verschiedene Eingabeformate.
BLTs besitzen großes Potenzial, benötigen jedoch weiterhin mehr Optimierung, umfangreichere Tests im großen Maßstab und verbesserte Software-Unterstützung, um ihre maximale Effizienz zu erreichen. Künftige Fortschritte bei Skalierungsgesetzen, Modell-Patching und der Integration in bestehende Deep-Learning-Frameworks könnten helfen, diese Hürden zu überwinden.
Auch wenn sich BLTs noch in der Weiterentwicklung befinden, deuten erste Ergebnisse darauf hin, dass sie traditionelle Transformer-Modelle im großen Maßstab erreichen oder sogar übertreffen können. Während KI die Grenzen von Effizienz und Anpassungsfähigkeit weiter verschiebt, könnten BLTs eine wichtige Rolle für die Zukunft der natürlichen Sprachverarbeitung spielen.
