
Byte Latent Transformers (BLT): A Tokenizer-Free Approach to Language Models
Large language models (LLMs) have traditionally depended on tokenization to handle long sentences or phrases by splitting them into smaller tokens, which are then processed by machine learning models. However, this method introduces issues such as bias in token compression, vulnerability to noise, and difficulties with multilingual text. But what if tokenization could be removed entirely, allowing models to train directly on raw bytes without losing efficiency or performance?
This article explores Byte Latent Transformers, a tokenizer-free or byte-level LLM architecture known as BLT.
Rather than relying on a fixed token vocabulary, byte latent transformers group bytes dynamically into latent patches. This lets the model assign computational effort where it is most needed, improving both efficiency and resilience. Compared with earlier approaches, BLT models handle noisy input better, capture character-level patterns more effectively, and process multiple languages with greater efficiency.
Prerequisites
Familiarity with the concepts below will make it easier to understand Byte Latent Transformers.
Tokenization in Language Models
- Conventional LLMs such as GPT and Llama use subword tokenization methods like Byte Pair Encoding (BPE) or WordPiece to split text into tokens before training.
- These tokens are predefined segments of words or characters that the model learns during training.
Transformer Architecture Basics
The transformer serves as the foundation of most modern LLMs. Its core parts include:
- Self-attention (how models focus on different parts of input data).
- Feed-forward layers (used for learning patterns in data).
Entropy in Language Models
- Entropy reflects uncertainty in predictions. High entropy indicates the model is unsure about the next byte or token, while low entropy indicates stronger confidence.
- In BLT, entropy is used to decide patch boundaries dynamically.
What Are Byte Latent Transformers?
Byte Latent Transformers (BLTs) remove the need for predefined tokenization. Traditional AI systems, including those used in Llama 2 and Llama 3, depend on tokenizers to divide text into smaller units before passing it into the model. Although this works effectively, it becomes restrictive when handling many languages or unfamiliar types of data.
BLTs instead operate on raw bytes and organize them into “patches” rather than fixed tokens. This patch-based method gives the model greater flexibility and efficiency while lowering the computational cost of text processing. Because larger patches reduce the number of required processing steps, BLTs can scale more effectively without dramatically raising training costs. This makes them especially valuable for large datasets and linguistically complex inputs, while also improving inference speed.
Although BLTs are still under refinement, early findings indicate that they can equal or even exceed the performance of conventional models at scale. As development continues, BLTs may lead to AI models that are both more efficient and more universally adaptable.
What Is Entropy Patching?
To begin, it helps to understand what entropy means in the context of BLT. Here, entropy represents the degree of uncertainty in the byte sequences being processed. Put simply, it describes how uncertain the model is about the next byte in a sequence.
- If entropy is high, the model is less certain about what byte comes next.
- If entropy is low, the model has greater confidence in the next byte.
- Entropy measures how much randomness or unpredictability exists in a sequence of bytes. In BLT, the entropy of a byte sequence affects:
- Compression Efficiency: Higher entropy introduces more unique patterns, making compression more difficult. Lower entropy indicates more predictable structures that can be encoded efficiently.
- Model Complexity Control: BLTs adjust computation based on entropy, deciding when to use the Latent Global Transformer and avoiding unnecessary processing.
- Representation Learning: By identifying patterns in byte sequences, BLTs learn representations that balance complexity with expressiveness.
Entropy patching is a technique for determining where byte sequences should be divided into patches based on the uncertainty of the next-byte prediction. This allows boundaries between patches to be chosen dynamically. Unlike rigid rule-based approaches such as splitting on whitespace, entropy patching uses a data-driven method, estimating entropy to locate positions where predicting the next byte becomes uncertain or more complex.
How Is Entropy Used for Patch Boundaries?
BLTs rely on a small byte-level language model (LM) to estimate the entropy of each byte in a sequence. This is calculated for every byte (xi) and helps determine where the sequence should be split into patches.
Equation for Entropy (H(xi))
The entropy (H(xi)) for each byte (xi) is calculated as follows:
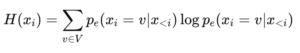
This computation enables the model to determine patch boundaries adaptively based on where the data becomes uncertain or complex. By placing boundaries in high-entropy regions, BLTs avoid wasting computation on predictable sections of the input. The more uncertain the next byte prediction is, the more likely the model is to start a new patch.
Subword Tokenization in LLMs
Modern large language models, including Llama 3, use subword tokenization. In this approach, text is broken into smaller units, but those units are not always complete words. Instead, they may consist of word fragments, syllables, or even smaller pieces. The tokenizer uses a predefined inventory of pieces learned from training data. These pieces are fixed and do not change dynamically.
Patches vs. Tokens
Unlike tokens, patches are byte sequences that are formed dynamically while the model is operating. This means they are not tied to a fixed vocabulary and may differ depending on the input. In token-based systems, the model does not directly access the underlying raw bytes. With patches, however, the model works directly with raw bytes and groups them on the fly.
BLT’s Advantage Over Tokenization
In traditional tokenization-based models, increasing the vocabulary size usually leads to larger tokens. This reduces the number of processing steps, but it also increases computational demands. BLT changes this tradeoff by providing greater flexibility in how data is grouped and processed, which can improve efficiency in certain scenarios.
How Does BLT Decide When to Split the Data?
When BLTs generate text, they must decide in real time whether the current data should begin a new patch. This decision is made incrementally, using only the information already processed, without access to future bytes. This matters because BLT follows a dynamic strategy and cannot look ahead in the sequence when deciding how to split the data. It must make patching decisions step by step, a process known as incremental patching.
Why Doesn’t Tokenization Work the Same Way?
Standard tokenization does not operate incrementally in the same manner. For example, when a tokenizer begins processing the start of a word, the final token split may depend on the characters that come later in that word. In other words, tokenization can depend on future context. That does not satisfy the needs of a system like BLT, where each decision must be made without knowledge of what follows.
Architecture and Mechanisms: A Simple Breakdown
Byte latent transformers include three main components:
- Global Transformer Model (Latent Global Transformer)
- Local Encoder (Transforms bytes into patches)
- Local Decoder (Converts patches back into bytes)
Each part plays an essential role in making BLT both efficient and scalable for language processing.
1. Global Transformer Model (Latent Global Transformer)
- This is the central processing unit of the BLT. It handles sequences of patch representations instead of individual bytes.
- It works autoregressively, meaning it predicts the next patch from the patches that came before it.
- It uses a block-causal attention mask so the model only attends to the current and previous patches, which improves efficiency.
- Because this is the most computationally demanding component, BLT carefully determines when it should be used, optimizing cost according to the complexity of the input.
2. Local Encoder (Converting Bytes into Patches)
- This is a smaller and lighter transformer responsible for turning raw bytes into patch representations.
- It uses a dedicated cross-attention mechanism to pool byte information efficiently into patches.
- It includes hash-based n-gram embeddings, allowing it to capture patterns across several consecutive bytes (from 3 to 8 bytes) to improve representation quality.
- It also uses a block-causal attention mask within local regions, meaning each byte only focuses on nearby bytes while patches are being formed.
3. Local Decoder (Converting Patches Back to Bytes)
- This is another lightweight transformer, but it performs the reverse task of the encoder.
- It takes processed patch representations and reconstructs the original byte sequences.
- It uses cross-attention so that patch representations guide generation at the byte level.
- It preserves output quality by refining byte details inside each patch.
How BLT Works Together
Encoding Phase
- The Local Encoder groups bytes into patches by identifying patterns and compressing information efficiently.
- Hash-based n-gram embeddings help it capture broader context without increasing computational cost.
Processing Phase
- The Global Transformer works on patch representations instead of raw bytes, which makes the computation more efficient.
- It uses adaptive patch sizing, allowing the model to spend more computational effort on difficult text and less on predictable text.
Decoding Phase
- The Local Decoder reconstructs the original byte sequence from the processed patches through cross-attention.
Challenges
Although BLTs provide several benefits over traditional transformers, they also introduce a number of limitations:
- BLTs currently depend on scaling laws originally designed for BPE-based transformers, which may not be ideal for their architecture. Further research is needed to create BLT-specific scaling laws that could improve both efficiency and performance.
- Current deep learning libraries are heavily optimized for tokenizer-based models, making it challenging for BLTs to achieve the same efficiency level.
- BLTs require specialized implementations such as FlexAttention, yet they may still fall short of BPE-based models in wall-clock performance.
- Initial experiments suggest that converting tokenizer-based models such as Llama 3 into byte-level systems is possible, but the process remains insufficiently optimized.
- Additional research is necessary to ensure BLTs can match or exceed tokenizer-based models without requiring full retraining.
FAQs on Byte Latent Transformers (BLTs)
1. How does BLT differ from traditional transformers?
Traditional transformers rely on tokenization, where text is split into smaller units such as words or subwords before processing. BLTs instead work directly with byte sequences and organize them into patches. This removes the need for tokenization and enables BLTs to operate efficiently across any language or dataset without depending on predefined vocabularies.
2. What are the benefits of BLT over tokenization?
- Greater Flexibility: It works with any language or text format without requiring a tokenizer.
- Improved Efficiency: Larger byte patches lower computational overhead and improve scaling.
- Better Performance at Scale: BLTs can match or outperform token-based models as model size increases.
- Reduced Preprocessing: There is no need to train and fine-tune separate tokenizers for different languages.
3. Is BLT suitable for multilingual data?
Yes. Because BLTs operate on raw bytes instead of language-specific tokens, they can naturally support many languages, including those with complex writing systems. This makes them especially useful for multilingual AI models, since they eliminate the need for separate tokenization rules for each language.
4. Can BLT be integrated with existing AI models?
Yes, BLTs can be integrated into existing AI architectures, and early experiments show encouraging results when converting tokenizer-based systems such as Llama 3 into byte-level models. Although more optimization is still required, future progress may allow BLTs to be adopted in current AI workflows without retraining everything from the beginning.
Conclusions
The Byte Latent Transformer (BLT) marks an important change in how models can process raw data at the byte level. By replacing fixed tokens with dynamic patches guided by entropy, BLT provides a more flexible and efficient way to manage diverse data and varying computational requirements. This approach enables finer-grained understanding of data, stronger computational efficiency, and greater adaptability across different input formats.
BLTs offer considerable promise, but they still need more optimization, broader testing at scale, and better software support before reaching maximum efficiency. Future progress in scaling laws, model patching, and integration with existing deep learning frameworks may help address these obstacles.
Although BLTs are still developing, early evidence suggests they can rival or even surpass traditional transformer models at scale. As AI continues to advance toward greater efficiency and adaptability, BLTs may become an important part of the future of natural language processing.
