
Sliding Window Attention: Eine effiziente Methode für lange Sequenzen in modernen Sprachmodellen
Moderne Sprachmodelle arbeiten weniger effizient, sobald Eingabesequenzen sehr lang werden, weil klassische Attention-Mechanismen quadratisch mit der Sequenzlänge skalieren. Das verursacht hohe Rechenkosten und einen erheblichen Speicherbedarf. Sliding Window Attention bietet dafür eine praxisnahe Lösung. Anstatt jedem Token zu erlauben, auf die gesamte Sequenz zuzugreifen, wird die Aufmerksamkeit auf einen festen lokalen Kontext begrenzt. Dadurch sinken sowohl der Rechenaufwand als auch der Speicherverbrauch, während wichtige Abhängigkeiten weiterhin erhalten bleiben.
Statt dass jedes Token mit allen anderen Tokens interagiert, beschränkt Sliding Window Attention die Aufmerksamkeit auf nahegelegene Nachbarn innerhalb eines definierten Fensters. Dieses Prinzip ähnelt der menschlichen Art, Informationen zunächst lokal zu verarbeiten, bevor ein umfassenderes Gesamtverständnis entsteht.
Die zugrunde liegende Forschung beschreibt zwei zentrale Gruppen von Methoden, die entwickelt wurden, um lange Sequenzen effizienter zu verarbeiten. Diese lassen sich im Allgemeinen in zwei Kategorien einteilen: Sparse-Attention-Ansätze, die die Anzahl der Attention-Berechnungen verringern, sowie rekurrente Ansätze wie lineare Attention und State-Space-Modelle, die Sequenzen über versteckte Zustände verarbeiten. Beide Richtungen bringen jedoch Kompromisse mit sich. Entweder leidet die Leistung zugunsten der Effizienz, oder es entstehen komplexere Architekturen, die schwerer zu implementieren und bereitzustellen sind. Deshalb wächst der Bedarf an einfacheren und gleichzeitig effizienten Lösungen, die nah an der klassischen Transformer-Architektur bleiben, ohne sie unnötig zu verkomplizieren.
Wichtige Erkenntnisse
- Sliding Window Attention senkt den Rechenaufwand von O(n2) auf O(n⋅w) und macht die Verarbeitung langer Sequenzen dadurch deutlich praktikabler.
- Der Fokus liegt auf lokalem Kontext, während tiefere Schichten Informationen weiterreichen, sodass auch größere Abhängigkeiten erfasst werden können.
- Longformer erweitert dieses Prinzip durch globale Attention, wodurch ausgewählte Tokens auf die komplette Sequenz zugreifen können.
- Mistral verbessert Sliding Window Attention für den praktischen Einsatz mit einem effizienten KV-Cache und schnellerer Inferenz.
- SWAT optimiert Sliding Window Attention mit Sigmoid-Attention, balanciertem ALiBi und RoPE für mehr Stabilität und ein besseres Positionsverständnis.
- Trotz dieser Fortschritte bleiben bei allen Verfahren Kompromisse zwischen Effizienz, Genauigkeit und Komplexität bestehen.
- Bei sehr langen Sequenzen liefern Kombinationen mit speicherbasierten oder hybriden Verfahren häufig die besten Ergebnisse.
Wie klassische Attention funktioniert
Um Sliding Window Attention zu verstehen, hilft es zunächst, die Standardform der Self-Attention zu betrachten.
In einem Transformer wird jedes Token in drei Vektoren umgewandelt: Query Q, Key K und Value V. Die Attention wird dann wie folgt berechnet:
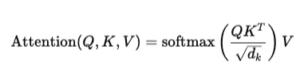
In diesem Aufbau wird jedes Token mit jedem anderen Token verglichen. Hat die Sequenz die Länge n, dann besitzt die Attention-Matrix die Größe n×n, was zu einer Komplexität von O(n2) führt.
Gerade bei langen Dokumenten, Retrieval-Augmented-Generation-Pipelines oder KI-Systemen mit großen Kontextfenstern wird das schnell zum Engpass.
Wichtige Grundbegriffe
Quadratische Komplexität: Bei klassischer Attention interagiert jedes Token mit jedem anderen Token, was zu einer Berechnungskomplexität von O(n2) führt. Mit wachsender Sequenzlänge wird das sehr teuer, weshalb effizientere Methoden wie Sliding Window Attention notwendig sind.
Causal Mask: Eine Causal Mask sorgt dafür, dass ein Token nur auf frühere Tokens und nicht auf zukünftige zugreifen kann. Das ist für autoregressive Modelle, etwa bei der Textgenerierung, entscheidend, damit keine Informationen aus der Zukunft einfließen.
Softmax: Softmax wandelt Attention-Scores in Wahrscheinlichkeiten um, deren Summe 1 ergibt. Dadurch entsteht Konkurrenz zwischen Tokens: Erhält ein Token viel Aufmerksamkeit, fallen die Gewichte der anderen entsprechend kleiner aus.
Attention-Sink-Phänomen: In manchen Fällen bekommen bestimmte Tokens, zum Beispiel Satzzeichen oder spezielle Marker, dauerhaft hohe Aufmerksamkeit, obwohl sie inhaltlich wenig relevant sind. Solche Attention Sinks können die Effizienz verringern und den Fokus von wichtigem Kontext ablenken.
KV-Cache (Key-Value-Cache): Während der Textgenerierung speichern Modelle frühere Keys und Values, damit diese nicht in jedem Schritt neu berechnet werden müssen. Das beschleunigt die Inferenz deutlich, besonders bei langen Sequenzen, und wird in Modellen wie Mistral gezielt optimiert.
Was ist Sliding Window Attention?
Sliding Window Attention begrenzt die Aufmerksamkeit auf ein lokales Fenster der Größe w. Jedes Token berücksichtigt nur Tokens innerhalb eines festen Bereichs vor und nach seiner Position.
Wird Token i verarbeitet, dann kann es nur auf Tokens im folgenden Bereich zugreifen:
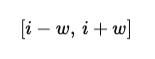
Dadurch verändert sich die Komplexität von:
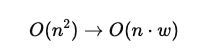
Da w≪n gilt, ist dieses Verfahren wesentlich effizienter als vollständige Attention. Um die Komplexität zu senken und gleichzeitig die sequentielle Information zu bewahren, wurde Sliding Window Attention unter anderem in Longformer eingeführt.
Vergleich der Komplexität
Volle Attention besitzt die Komplexität O(n2)
Sliding Window Attention reduziert diese auf:
O(n⋅w)
Wenn n=10.000 und w=512, dann gilt:
n2=100.000.000, n⋅w=5.120.000
Das entspricht nahezu einer 20-fachen Verringerung des Rechenaufwands.
Man kann sich ein Sliding Window der Größe 3 vorstellen, das sich über einen Satz bewegt, wie in der Abbildung dargestellt. Zu jedem Zeitpunkt kann das Modell nur 3 Tokens gleichzeitig sehen; diese werden als aktive Tokens bezeichnet, zum Beispiel „a dear little“.
Tokens außerhalb dieses Fensters sind nicht direkt sichtbar und werden als verdrängte Tokens bezeichnet. Ihre Information geht jedoch nicht vollständig verloren. Ein Teil davon wird über jede Transformer-Schicht an benachbarte Tokens weitergegeben. Das bedeutet: Selbst wenn ein Token das Fenster verlässt, bleiben Spuren seiner Bedeutung über benachbarte Tokens erhalten.
Mit zunehmender Tiefe des Modells und zusätzlichen Schichten breitet sich diese Information weiter aus. Der gesamte Wirkungsbereich eines Tokens wächst mit der Tiefe und lässt sich wie folgt berechnen:
Bei einer Fenstergröße von ω=3 und einer Tiefe von L=2 ergibt sich:
Einfach gesagt: Auch wenn das Modell jeweils nur 3 Tokens gleichzeitig betrachtet, kann es nach 2 Schichten effektiv Informationen über bis zu 5 Tokens hinweg erfassen.
SWAT Attention einfach erklärt
Was SWAT erreichen soll
SWAT ist ein angepasster Attention-Mechanismus, der Sliding Window Attention stabiler und wirkungsvoller machen soll. Er verbessert gleichzeitig drei zentrale Bereiche: die Berechnung der Attention-Gewichte, die Einbindung von Positionsinformationen und die Fähigkeit von Tokens, innerhalb eines begrenzten Fensters sinnvollen Kontext zu behalten.
Schritt 1: Softmax durch Sigmoid ersetzen
In klassischen Transformern wird Attention mit Softmax berechnet:
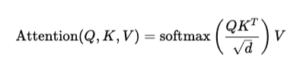
Das Problem bei Softmax besteht darin, dass Tokens miteinander konkurrieren. Erhält ein Token hohe Aufmerksamkeit, verlieren andere Tokens an Gewicht.
SWAT ersetzt Softmax durch Sigmoid:
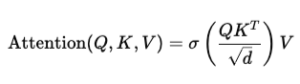
Hier ist σ\sigmaσ die Sigmoid-Funktion.
Das bedeutet:
- Jedes Token erhält Aufmerksamkeit unabhängig von den anderen
- Tokens unterdrücken sich nicht gegenseitig
- Mehrere Tokens können gleichzeitig wichtig sein
Statt also nur das wichtigste Token auszuwählen, kann der Mechanismus mehrere relevante Tokens parallel berücksichtigen.
Schritt 2: Positionsbias mit balanciertem ALiBi hinzufügen
Da Sigmoid Positionspräferenzen nicht so natürlich kodiert wie Softmax, ergänzt SWAT einen Positionsbias:
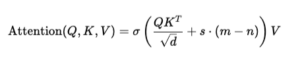
Dabei gilt:
- m = aktuelle Token-Position
- n = Position des Nachbartokens
- s = Steigung, die bestimmt, wie stark Positionen gewichtet werden
Der Ausdruck s⋅(m−n) zeigt dem Modell, wie weit zwei Tokens voneinander entfernt sind.
Kernidee
SWAT nutzt balanciertes ALiBi. Das bedeutet:
- Die Hälfte der Attention-Heads blickt nach vorn auf zukünftige Tokens
- Die andere Hälfte blickt zurück auf frühere Tokens
Die Steigungen lauten:

Dadurch wird Folgendes möglich:
- Einige Heads konzentrieren sich auf aktuelle oder nahe Tokens
- Andere Heads richten den Fokus stärker auf weiter zurückliegende Tokens
Dadurch kann das Modell sowohl kurzfristige als auch langfristige Muster lernen.
Schritt 3: RoPE für eine stärkere Positionskodierung ergänzen
Selbst mit ALiBi bleiben Positionssignale vergleichsweise schwach.
Deshalb ergänzt SWAT zusätzlich RoPE (Rotary Positional Embedding), das Query- und Key-Vektoren abhängig von ihrer Position rotiert.
Die endgültige Attention lautet dann:
Was das vereinfacht bedeutet
- Es werden nur Tokens innerhalb des Sliding Windows berücksichtigt
- Queries und Keys werden rotiert, um Positionsinformationen einzubinden
- Ein distanzbasierter Bias wird ergänzt
- Sigmoid berechnet die Attention-Gewichte
- Values werden kombiniert, um das Ergebnis zu erzeugen
SWAT lässt sich vereinfacht so verstehen:
- Sliding Window → begrenzt, wie viel Kontext betrachtet wird
- Sigmoid → erlaubt mehreren Tokens gleichzeitig relevant zu sein
- ALiBi → ergänzt ein Verständnis für Distanz
- RoPE → stärkt das Verständnis für Positionen
Schritt 4: Effizienz von SWAT
Trotz dieser Erweiterungen bleibt SWAT effizient.
Die Kosten betragen:
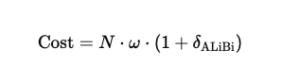
Dabei gilt:
- N = Sequenzlänge
- ω = Fenstergröße
- δALiBi = ein kleiner zusätzlicher Aufwand
Da δALiBi sehr klein ist, bleibt die Komplexität bei:
O(N⋅ω), sodass das Verfahren linear und skalierbar bleibt. SWAT macht Sliding Window Attention leistungsfähiger, indem Tokens über Sigmoid kooperieren können, Distanzen über ALiBi besser verstehen und Positionen mithilfe von RoPE sauber kodiert werden – und das alles bei gleichzeitig hoher Effizienz.
Sliding Window Attention funktioniert deshalb so gut, weil viele sprachliche Abhängigkeiten lokal sind. Wörter hängen meist stärker von benachbarten Wörtern ab als von weit entfernten. Diese Annahme erlaubt es Modellen, eine starke Leistung zu erhalten und gleichzeitig die Rechenkosten deutlich zu senken.
Sliding Window Attention in modernen Architekturen
Longformer: Lokale Attention mit globalem Kontext erweitern
Longformer erweitert das Konzept der Sliding-Window-Attention, indem es deren Einschränkungen bei der Modellierung langfristiger Beziehungen adressiert. Während klassische Sliding-Window-Attention nur einen festen lokalen Kontext um jedes Token berücksichtigt, führt Longformer einen hybriden Attention-Mechanismus ein, der effiziente lokale Attention mit gezielt zugewiesener globaler Attention kombiniert. Dadurch kann das Modell sowohl nahe Kontextinformationen als auch wichtige Abhängigkeiten über größere Distanzen erfassen und deutlich längere Sequenzen verarbeiten, ohne die quadratischen Rechenkosten traditioneller Self-Attention zu verursachen.
In Longformer verwenden die meisten Tokens weiterhin Sliding Window Attention. Ein Token an Position i greift auf Tokens innerhalb einer Fenstergröße w zu, genau wie zuvor beschrieben:
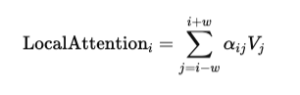
Zusätzlich führt Longformer jedoch eine zweite Form von Attention ein: die globale Attention. Bestimmte Tokens werden als globale Tokens markiert. Diese können auf alle anderen Tokens der Sequenz zugreifen, und gleichzeitig können alle Tokens auch auf sie zugreifen.
Mathematisch ergibt sich für ein Token i, wenn G die Menge der globalen Tokens bezeichnet:
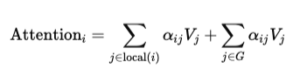
Diese einfache Erweiterung beseitigt eine der größten Schwächen von Sliding Window Attention. Informationen müssen nicht mehr Schicht für Schicht über große Distanzen weitergegeben werden. Stattdessen fungieren globale Tokens als Informationsknoten. In langen Dokumenten können etwa Titel, Abschnittsüberschriften oder Fragetokens in QA-Aufgaben als globale Tokens definiert werden. Diese sammeln Informationen aus der gesamten Sequenz und verteilen sie effizient weiter.
Das führt zu einer Komplexität von:
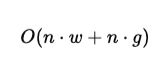
wobei g die Anzahl der globalen Tokens ist. Da g in der Regel klein bleibt, bleibt auch das Modell effizient und gewinnt gleichzeitig globale Kontextfähigkeit.
Die wesentliche Verbesserung von Longformer besteht in genau dieser Balance zwischen Effizienz und globalem Verständnis. Die Skalierbarkeit von Sliding Window Attention bleibt erhalten, während an entscheidenden Stellen wieder vollständiger Kontext eingebunden wird.
Mistral Sliding Window Attention
Mistral entwickelt Sliding Window Attention weiter, indem der Ansatz gezielt auf praktische Effizienz ausgelegt wird, insbesondere während der Inferenz. Es geht dabei nicht nur um die Begrenzung der Attention, sondern auch darum, wie Speicher über den KV-Cache verwaltet wird. In der Mistral-Architektur wird Sliding Window Attention mit einer festen Attention-Spanne umgesetzt. Jedes Token berücksichtigt nur eine feste Anzahl vorheriger Tokens und nicht die gesamte Sequenz. Das ist besonders bei autoregressiver Generierung wichtig.
Wenn die Fenstergröße w beträgt, dann greift das Modell zum Zeitpunkt t nur auf Folgendes zu:
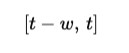
Das bedeutet, dass nicht mehr der vollständige KV-Cache der Größe t gespeichert werden muss, sondern nur die zuletzt relevanten Tokens. Dadurch sinkt der Speicherbedarf während der Inferenz erheblich.
Formal reduziert sich die Größe des KV-Caches von:
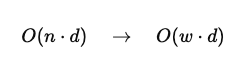
wobei d die versteckte Dimension bezeichnet.
Eine weitere wichtige Verbesserung in Mistral ist der Einsatz von Grouped Query Attention (GQA). Anstatt für jeden Attention-Head separate Key- und Value-Projektionen zu verwenden, teilen sich mehrere Query-Heads dieselben Key-Value-Paare. Das senkt den Bedarf an Speicherbandbreite und beschleunigt die Inferenz, ohne die Leistung stark zu verschlechtern.
Die Kombination aus Sliding Window Attention und GQA macht Mistral besonders effizient auf GPUs, was vor allem in Produktionsumgebungen mit optimierten KI-Workloads von Vorteil ist.
Im Unterschied zu Longformer führt Mistral keine expliziten globalen Tokens ein. Stattdessen verlässt sich das Modell auf tiefere Schichten und einen effizienten Informationsfluss, um Kontext weiterzutragen. Im Vordergrund stehen praktische Effizienz und starke reale Leistung statt zusätzlicher architektonischer Komplexität.
Was gegenüber einfacher Sliding Window Attention verbessert wurde
Der Übergang von einfacher Sliding-Window-Attention zu Architekturen wie Longformer und Mistral zeigt zwei unterschiedliche Weiterentwicklungen dieses Konzepts.
Longformer konzentriert sich darauf, lokale Attention ausdrucksstärker zu machen. Durch die Ergänzung globaler Attention kann das Modell Informationen erfassen, die über unmittelbar benachbarte Tokens hinausgehen, und langfristige Abhängigkeiten besser berücksichtigen. Das ist besonders hilfreich für Anwendungsfälle wie Dokumentenverständnis, Question Answering und Zusammenfassungen, bei denen ein größerer Kontext entscheidend ist.
Mistral verfolgt dagegen vor allem das Ziel praktischer Effizienz. Die Umsetzung der Sliding-Window-Attention ist für Inferenz optimiert, indem der Bedarf an KV-Cache reduziert und Grouped Query Attention genutzt wird. Dadurch kann das Modell schneller ausgeführt werden und gleichzeitig weniger Speicher verbrauchen, was es besonders geeignet für Produktivumgebungen und Systeme mit begrenzten GPU-Ressourcen macht.
Vereinfacht gesagt: Longformer erweitert, was lokale Attention verstehen kann, während Mistral verbessert, wie schnell und ressourcenschonend sie ausgeführt werden kann.
Grundlegende Einschränkungen
SWAT reagiert empfindlich auf Hyperparameter wie Fenstergröße, Tiefe und ALiBi-Steigungen, weshalb eine sorgfältige Abstimmung notwendig ist, um gute Ergebnisse zu erzielen. Wenn Modelle größer werden, können sie sich zudem stärker auf Memorierung als auf Kontext stützen, was die Wirkung von Sliding Window Attention abschwächen kann. Darüber hinaus ist der Attention-Bereich von SWAT durch Fenstergröße und Tiefe begrenzt, was bei sehr langen Sequenzen zu Informationsverlust führen kann. In solchen Fällen kann es notwendig sein, SWAT mit anderen Methoden wie Speichermechanismen oder hybriden Architekturen zu kombinieren.
FAQ
Was ist Sliding Window Attention und warum ist sie nützlich?
Sliding Window Attention begrenzt jedes Token darauf, nur nahegelegene Tokens statt der gesamten Sequenz zu berücksichtigen. Dadurch sinkt der Rechenaufwand von quadratisch auf linear, was lange Eingaben wesentlich effizienter verarbeitbar macht. Das funktioniert gut, weil viele sprachliche Abhängigkeiten lokal sind.
Worin unterscheidet sich Sliding Window Attention von klassischer Attention?
Klassische Attention vergleicht jedes Token mit jedem anderen Token, was rechnerisch teuer ist. Sliding Window Attention beschränkt sich auf eine feste lokale Nachbarschaft und spart dadurch sowohl Speicher als auch Rechenleistung. Der Nachteil besteht darin, dass weitreichende Abhängigkeiten nicht immer direkt erfasst werden.
Wie gelangt Information über das Fenster hinaus?
Auch wenn Tokens nur ein kleines lokales Fenster sehen, wird Information über die Schichten hinweg weitergereicht. Jede zusätzliche Schicht erweitert den Kontext ein Stück weiter, sodass tiefere Modelle einen größeren Bereich abdecken können. So entsteht indirekt auch ein Verständnis für weiter entfernte Zusammenhänge.
Welche Verbesserungen bringt Longformer?
Longformer ergänzt Sliding Windows um globale Attention. Bestimmte Tokens können dadurch die gesamte Sequenz berücksichtigen, was die Erfassung von Langstreckenabhängigkeiten deutlich verbessert. Dadurch eignet sich das Modell besser für Aufgaben wie das Verständnis langer Dokumente.
Was unterscheidet den Ansatz von Mistral?
Mistral konzentriert sich auf Effizienz während der Inferenz. Das Modell kombiniert Sliding Window Attention mit einem optimierten KV-Cache und Grouped Query Attention. Dadurch sinken Speicherbedarf und Generierungszeit.
Was ist SWAT und worin liegt der Unterschied?
SWAT führt mehrere architektonische Änderungen ein, um die Effizienz der Attention und die Stabilität des Trainings zu verbessern. Anstelle der klassischen Softmax-Funktion nutzt es einen sigmoidbasierten Attention-Mechanismus. Dadurch können Tokens unabhängig voneinander zur Attention beitragen, statt um einen festen Anteil an Aufmerksamkeit zu konkurrieren. Das hilft, Informationen besser zu erhalten und den Signalfluss im Netzwerk zu verbessern.
Zusätzlich kombiniert SWAT Balanced ALiBi (Attention with Linear Biases) mit Rotary Positional Embeddings (RoPE), um das Positionsverständnis und die Modellierung von Sequenzen zu stärken. Zusammengenommen führen diese Verbesserungen zu stabileren Trainingsdynamiken, besserer Informationsweitergabe und einer höheren Leistung bei Long-Context-Aufgaben.
Warum verwendet SWAT Sigmoid statt Softmax?
Traditionelle Softmax-Attention zwingt Tokens dazu, um Attention-Gewicht zu konkurrieren. Das bedeutet: Wenn einem Token mehr Aufmerksamkeit zugewiesen wird, erhalten andere automatisch weniger. Dadurch können potenziell wichtige Signale abgeschwächt oder unterdrückt werden.
Sigmoidbasierte Attention behandelt dagegen jedes Token unabhängig. So können mehrere Tokens gleichzeitig starke Aufmerksamkeit erhalten. Dieser Ansatz hilft dabei, mehr Kontextinformationen innerhalb des Attention-Fensters zu bewahren, was zu reichhaltigeren Repräsentationen und einem verbesserten Informationsfluss im gesamten Modell führt.
Was sind die wichtigsten Einschränkungen von SWAT?
SWAT reagiert empfindlich auf wichtige Hyperparameter, insbesondere auf die Größe des Attention-Fensters und die Modelltiefe, da beide die Leistung und das Trainingsverhalten maßgeblich beeinflussen können. Da der Attention-Mechanismus weiterhin lokal begrenzt ist, kann das Modell Schwierigkeiten haben, Informationen über sehr lange Sequenzen hinweg zu bewahren. Dadurch besteht das Risiko, dass wichtige langfristige Abhängigkeiten verloren gehen.
Darüber hinaus steigt mit zunehmender Modellgröße die Gefahr, dass Leistungsverbesserungen stärker auf dem Auswendiglernen von Trainingsdaten beruhen als auf tatsächlichen Fortschritten beim logischen Schlussfolgern oder bei der Generalisierungsfähigkeit.
Fazit
Sliding-Window-Attention bietet einen einfachen Ansatz, um Transformer besser für lange Eingabesequenzen nutzbar zu machen, indem die Attention auf nahegelegene Tokens begrenzt wird. Dieses Konzept wurde in Architekturen wie Longformer weiterentwickelt, der globales Reasoning ergänzt, sowie in Mistral, das vor allem auf praktische Effizienz ausgerichtet ist. SWAT baut auf dieser Grundlage auf, verbessert jedoch die Attention-Berechnung selbst sowie den Umgang mit Positionsinformationen und schafft dadurch eine stabilere und leistungsfähigere Methode.
Dennoch ist Long-Context-Verständnis durch keine einzelne Technik vollständig gelöst. Jeder Ansatz bringt Kompromisse zwischen Geschwindigkeit, Qualität und Implementierungskomplexität mit sich. In realen Systemen entstehen die besten Ergebnisse häufig durch die Kombination solcher Methoden mit speicherbasierten oder hybriden Designs – insbesondere in groß angelegten KI-Anwendungen wie Retrieval-Augmented-Generation-Pipelines oder Long-Context-Agenten.
