
Sliding Window Attention: An Efficient Way to Handle Long Sequences in Modern Language Models
Modern language models become less efficient when input sequences grow very large because traditional attention mechanisms scale quadratically with sequence length. This leads to high computational cost and heavy memory usage. Sliding window attention offers a practical way to address this issue. Instead of allowing every token to attend to the entire sequence, it restricts attention to a fixed local context. This lowers both compute and memory demands while still preserving useful dependencies.
Rather than having each token interact with all others, sliding window attention limits each token to nearby neighbors within a defined window. This concept is similar to how people often process information locally first before building a broader understanding.
The research discusses two major families of methods developed to process long sequences more efficiently. These usually fall into two groups: sparse attention approaches, which reduce the number of attention calculations, and recurrent-style approaches such as linear attention and state space models, which process sequences through hidden states. Both approaches introduce trade-offs. They may reduce performance in exchange for efficiency or require more complex architectures that are harder to implement and deploy. Because of this, there is increasing demand for simpler and more efficient solutions that remain close to the standard Transformer design without adding substantial complexity.
Key Takeaways
- Sliding window attention lowers computation from O(n2) to O(n⋅w), making long-sequence processing more practical.
- It concentrates on local context, while deeper layers help pass information forward so broader dependencies can still be captured.
- Longformer extends this idea with global attention, enabling selected tokens to access the full sequence.
- Mistral improves sliding window attention for practical deployment through an efficient KV cache and faster inference.
- SWAT strengthens sliding window attention with sigmoid attention, balanced ALiBi, and RoPE for better stability and positional understanding.
- Even with these improvements, every method still involves trade-offs between efficiency, accuracy, and complexity.
- For extremely long sequences, combining these methods with memory-based or hybrid solutions often produces the strongest results.
How Traditional Attention Works
To understand sliding window attention, it is useful to first understand standard self-attention.
In a Transformer, each token is transformed into three vectors: query Q, key K, and value V. Attention is then computed as:
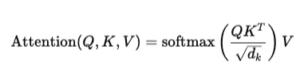
In this setup, every token is compared with every other token. If the sequence length is n, the attention matrix has size n×n, which results in O(n2) complexity.
This quickly becomes a bottleneck for long documents, retrieval-augmented generation pipelines, or AI systems that must work with large context windows.
Important Concepts to Know
Quadratic complexity: In standard attention, every token interacts with every other token, which leads to O(n2) computation. As sequence length grows, this becomes very expensive, which is why more efficient approaches such as sliding window attention are needed.
Causal mask: A causal mask ensures that a token can attend only to earlier tokens and not future ones. This is essential for autoregressive models, such as text generation systems, so they do not access information ahead of time.
Softmax: Softmax transforms attention scores into probabilities that add up to 1. This creates competition between tokens, so if one token receives high attention, the others receive smaller weights.
Attention sink phenomenon: In some cases, certain tokens such as punctuation or special markers receive consistently high attention even when they are not especially useful. These attention sinks can reduce efficiency and distract the model from more meaningful context.
KV cache (Key-Value cache): During text generation, models store previous keys and values so they do not have to recompute them at every step. This greatly speeds up inference, especially for long sequences, and is optimized in models such as Mistral.
What Is Sliding Window Attention?
Sliding window attention limits attention to a local window of size w. Each token attends only to other tokens within a fixed range before and after its position.
If token i is being processed, it can attend only to tokens in the range:
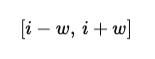
This changes the complexity from:
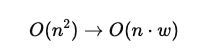
Because w≪n, this is much more efficient than full attention. To lower complexity while still preserving sequential information, sliding window attention was introduced in Longformer.
Complexity Comparison
Full attention has complexity O(n2)
Sliding window attention reduces this to:
O(n⋅w)
If n=10,000 and w=512, then:
n2=100,000,000, n⋅w=5,120,000
This is close to a 20x reduction in computation.
Imagine a sliding window of size 3 moving across a sentence, as shown in the figure. At any point, the model can only observe 3 tokens at once; these are the active tokens, such as “a dear little.”
Tokens outside the current window are not directly visible and are referred to as evicted tokens. Even so, their information is not entirely lost. Part of that information is passed forward to nearby tokens through each Transformer layer. This means that even after a token leaves the window, traces of its meaning can still be carried by its neighbors.
As the model gets deeper and more layers are added, this information spreads further. The total range a token can influence increases with depth and is calculated as:
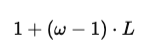
With window size ω=3 and depth L=2, the range becomes:
In simple terms, even if the model only looks at 3 tokens at a time, after 2 layers it can effectively capture information across as many as 5 tokens.
Understanding SWAT Attention in a Simple Way
What SWAT Is Designed to Achieve
SWAT is a modified attention mechanism created to make sliding window attention more stable and more effective. It improves three major aspects at once: how attention weights are calculated, how positional information is introduced, and how tokens preserve meaningful context within a limited window.
Step 1: Replacing Softmax with Sigmoid
In standard Transformers, attention uses softmax:
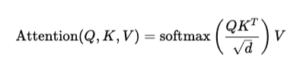
The issue with softmax is that it forces tokens to compete. If one token receives high attention, other tokens are reduced in importance.
SWAT replaces softmax with sigmoid:
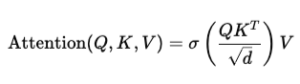
Here, σ\sigmaσ is the sigmoid function.
This means:
- Each token receives attention independently
- Tokens do not suppress one another
- Several tokens can be important at the same time
So instead of selecting only the single most important token, the mechanism can consider all relevant tokens together.
Step 2: Adding Positional Bias with Balanced ALiBi
Because sigmoid does not naturally encode positional preference the way softmax can, SWAT introduces a positional bias:
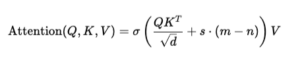
Here:
- m = current token position
- n = neighboring token position
- s = slope, which controls how strongly position matters
The term s⋅(m−n) tells the model how far apart two tokens are.
Key Idea
SWAT uses balanced ALiBi, which means:
- Half of the attention heads look forward toward future tokens
- Half of the attention heads look backward toward past tokens
The slopes are:

This allows:
- Some heads to focus on recent tokens
- Some heads to focus on older tokens
As a result, the model can learn both short-term and long-term patterns.
Step 3: Adding RoPE for Stronger Position Encoding
Even with ALiBi, positional signals remain relatively weak.
For that reason, SWAT also adds RoPE (Rotary Positional Embedding), which rotates query and key vectors according to token position.
The final attention becomes:
What This Means in Simple Terms
- Only tokens inside the sliding window are taken into account
- Queries and keys are rotated to include positional information
- A distance-based bias is added
- Sigmoid computes the attention weights
- Values are combined to generate the output
You can think of SWAT as:
- Sliding window → limits how much context is examined
- Sigmoid → allows multiple tokens to remain important
- ALiBi → adds awareness of distance
- RoPE → strengthens positional understanding
Step 4: Efficiency of SWAT
Despite these changes, SWAT remains efficient.
The cost is:
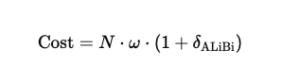
Where:
- N = sequence length
- ω = window size
- δALiBi = a small extra cost
Because δALiBi is very small, the complexity remains:
O(N⋅ω) so the method stays linear and scalable. SWAT makes sliding window attention more capable by allowing tokens to cooperate through sigmoid, understand distance through ALiBi, and encode position effectively through RoPE, all while maintaining efficiency.
Sliding window attention works well because many language dependencies are local. Words usually depend much more on nearby words than on distant ones. This assumption allows models to preserve strong performance while greatly reducing computational cost.
Sliding Window Attention in Modern Architectures
Longformer: Extending Local Attention with Global Context
Longformer extends the concept of sliding window attention by addressing its limitations in modeling long-range relationships. While standard sliding window attention focuses only on a fixed local context around each token, Longformer introduces a hybrid attention mechanism that combines efficient local attention with strategically assigned global attention. This allows the model to capture both nearby contextual information and important long-distance dependencies, enabling it to process much longer sequences without the quadratic computational cost of traditional self-attention.
In Longformer, most tokens still use sliding window attention. For a token at position i, it attends to tokens within a window size w, just as described earlier:
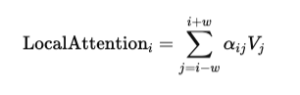
However, Longformer adds a second form of attention called global attention. Certain tokens are designated as global tokens, and these tokens can attend to all other tokens in the sequence, while all tokens can also attend to them.
Mathematically, if G represents the set of global tokens, then for any token i, the attention becomes:
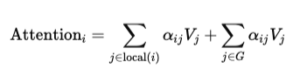
This simple addition solves one of the biggest weaknesses of sliding window attention. Information no longer has to move layer by layer across distant tokens. Instead, global tokens serve as information hubs. In a long document, for example, elements such as the title, section headings, or question tokens in QA tasks can be marked as global tokens. These tokens collect information from the full sequence and redistribute it efficiently.
This leads to a complexity of:
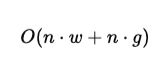
where g is the number of global tokens. Since g is usually small, the model remains efficient while gaining awareness of global context.
The major improvement introduced by Longformer is this balance between efficiency and global reasoning. It preserves the scalability of sliding window attention while selectively bringing back full-context awareness where it is most useful.
Mistral Sliding Window Attention
Mistral pushes sliding window attention further by optimizing it for practical efficiency, especially during inference. Its contribution is not only about limiting attention, but also about how memory is managed through the KV cache. In the Mistral architecture, sliding window attention is implemented with a fixed attention span. Each token attends only to a fixed number of previous tokens rather than the entire sequence. This is especially important during autoregressive generation.
If the window size is w, then at time step t, the model attends only to:
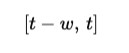
This means that instead of storing the entire KV cache of size t, the model only needs to keep the most recent tokens. This significantly reduces memory consumption during inference.
Formally, the KV cache size is reduced from:
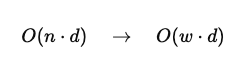
where d is the hidden dimension.
Another major improvement in Mistral is the use of Grouped Query Attention (GQA). Instead of assigning separate key and value projections to every attention head, multiple query heads share the same key-value pairs. This reduces memory bandwidth requirements and improves inference speed without significantly hurting performance.
The combination of sliding window attention and GQA makes Mistral highly efficient on GPUs, which is especially useful in production environments where AI workloads must be optimized carefully.
Unlike Longformer, Mistral does not explicitly add global tokens. Instead, it relies on deeper layers and efficient information flow to carry context forward. Its priority is practical efficiency and strong real-world performance rather than architectural complexity.
What Improved Over Basic Sliding Window Attention
The move from basic sliding window attention toward architectures like Longformer and Mistral illustrates two different ways this concept has been advanced.
Longformer focuses on making local attention more expressive. By adding global attention, it can capture information beyond nearby tokens and better handle long-range relationships. This is especially useful for use cases such as document understanding, question answering, and summarization, where the broader context plays an important role.
Mistral, on the other hand, focuses on practical efficiency. Its implementation of sliding window attention is optimized for inference by reducing KV cache requirements and using grouped query attention. As a result, it can run faster while using less memory, which makes it well suited for production environments and systems with limited GPU resources.
Put simply, Longformer extends what local attention can understand, while Mistral improves how quickly and resource-efficiently it can run.
Basic Limitations
SWAT is sensitive to hyperparameters such as window size, depth, and ALiBi slopes, so it requires careful tuning to perform well. As models become larger, they may depend more on memorization than on context, which can reduce the impact of sliding window attention. In addition, SWAT has a limited attention range determined by window size and depth, which can result in information loss for very long sequences. In such scenarios, it may need to be combined with other techniques such as memory mechanisms or hybrid architectures.
FAQ
What is sliding window attention and why is it useful?
Sliding window attention restricts each token so it attends only to nearby tokens instead of the full sequence. This reduces computation from quadratic to linear, making it much more efficient for long inputs. It works well because many language dependencies are local.
How is sliding window attention different from standard attention?
Standard attention compares every token with every other token, which is computationally expensive. Sliding window attention limits attention to a fixed neighborhood, saving both memory and compute. The trade-off is that long-range dependencies may be harder to capture directly.
How does information travel beyond the window?
Even though tokens can see only a small local window, information moves through layers. Each additional layer spreads context a bit farther, so deeper models can cover a broader range. This enables indirect long-range understanding.
What improvements does Longformer bring?
Longformer adds global attention on top of sliding windows. Certain tokens can attend to the entire sequence, which helps the model capture long-range dependencies more effectively. This makes it more capable for tasks such as document understanding.
What makes Mistral’s approach different?
Mistral focuses on inference efficiency. It combines sliding window attention with an optimized KV cache and grouped query attention. This reduces memory use and speeds up generation.
What is SWAT and how is it different?
SWAT introduces several architectural changes to improve attention efficiency and training stability. Instead of using the traditional softmax function, it employs a sigmoid-based attention mechanism, allowing tokens to contribute independently rather than competing for a fixed share of attention. This helps preserve information and improves the flow of signals across the network.
In addition, SWAT combines balanced ALiBi (Attention with Linear Biases) and Rotary Positional Embeddings (RoPE) to strengthen positional awareness and sequence modeling. Together, these enhancements lead to more stable training dynamics, better information propagation, and improved performance on long-context tasks.
Why does SWAT use sigmoid instead of softmax?
Traditional softmax attention forces tokens to compete for attention weight, meaning that increasing attention to one token automatically reduces attention allocated to others. As a result, potentially valuable signals can be weakened or suppressed.
By contrast, sigmoid-based attention treats each token independently, allowing multiple tokens to receive strong attention simultaneously. This approach helps retain more contextual information within the attention window, leading to richer representations and improved information flow throughout the model.
What are the main limitations of SWAT?
SWAT is sensitive to key hyperparameters, particularly attention window size and model depth, which can significantly influence performance and training behavior. Because its attention mechanism remains locally constrained, the model may struggle to retain information across extremely long sequences, potentially leading to the loss of important long-range dependencies. Additionally, as model size increases, there is a greater risk that performance gains may rely more heavily on memorization rather than improved reasoning or generalization capabilities.
Conclusion
Sliding window attention offers a straightforward way to make Transformers better suited for long input sequences by limiting attention to nearby tokens. The concept has been developed further in architectures such as Longformer, which introduces global reasoning, and Mistral, which focuses on practical efficiency. SWAT builds on this foundation by improving the attention calculation itself and the treatment of positional information, resulting in a more stable and effective method.
Still, long-context understanding is not fully solved by any single technique. Every approach involves trade-offs between speed, quality, and implementation complexity. In real-world systems, the strongest results often come from combining these methods with memory-based or hybrid designs, particularly in large-scale AI applications such as retrieval-augmented generation pipelines or long-context agents.
